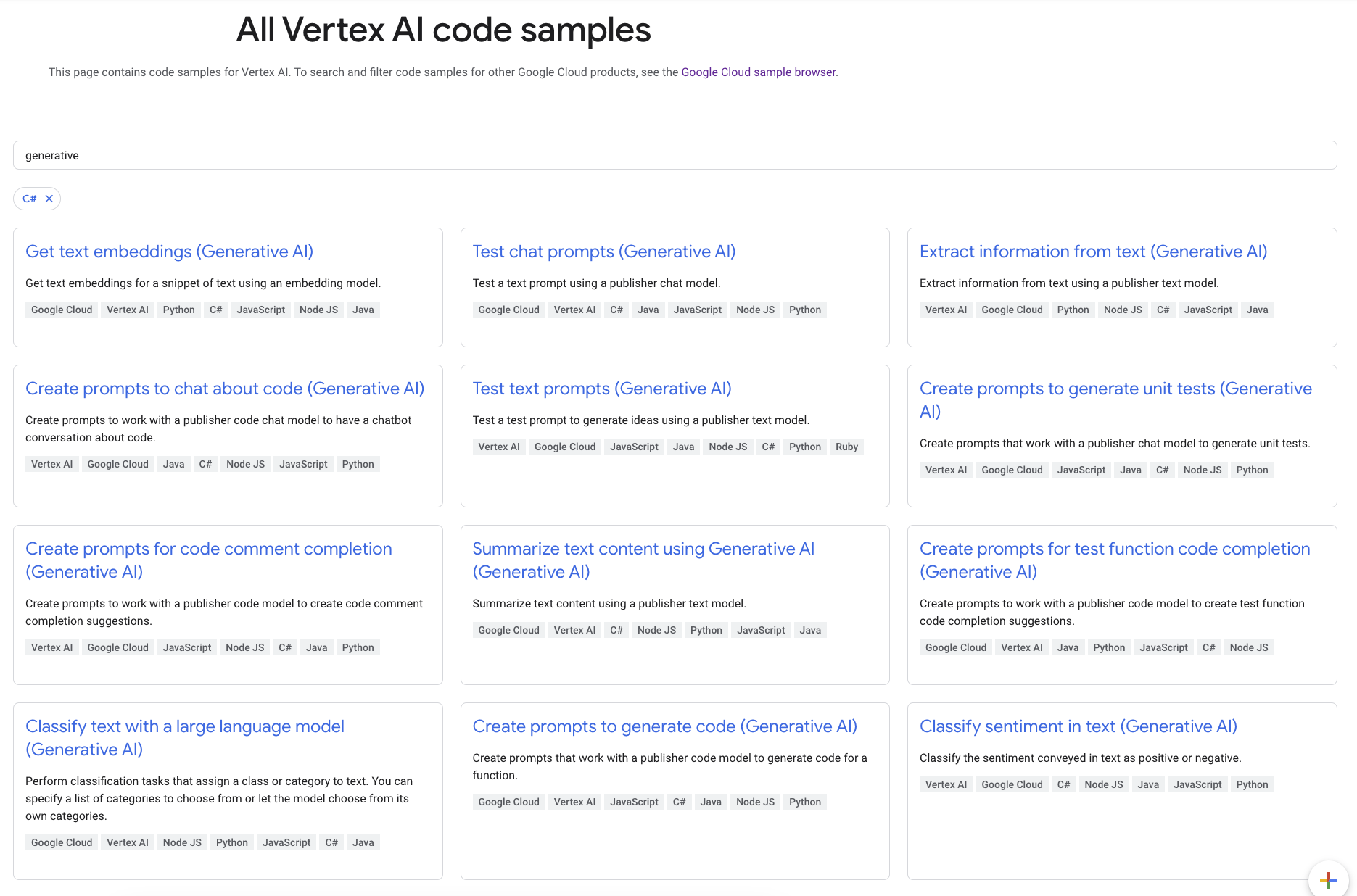
![]()
In the Create and deploy a new web app to Cloud Run with Duet AI post, I created a simple web application and deployed to Cloud Run using Duet AI’s help. Duet AI has been great to get a new and simple app up and running. But does it help for existing apps? Let’s figure it out.
In this blog post, I take an existing web app, explore it, test it, add a unit test, add new functionality, and add more unit tests all with the help of Duet AI. Again, I captured some lessons learned along the way to get the most out of Duet AI.
Read More →