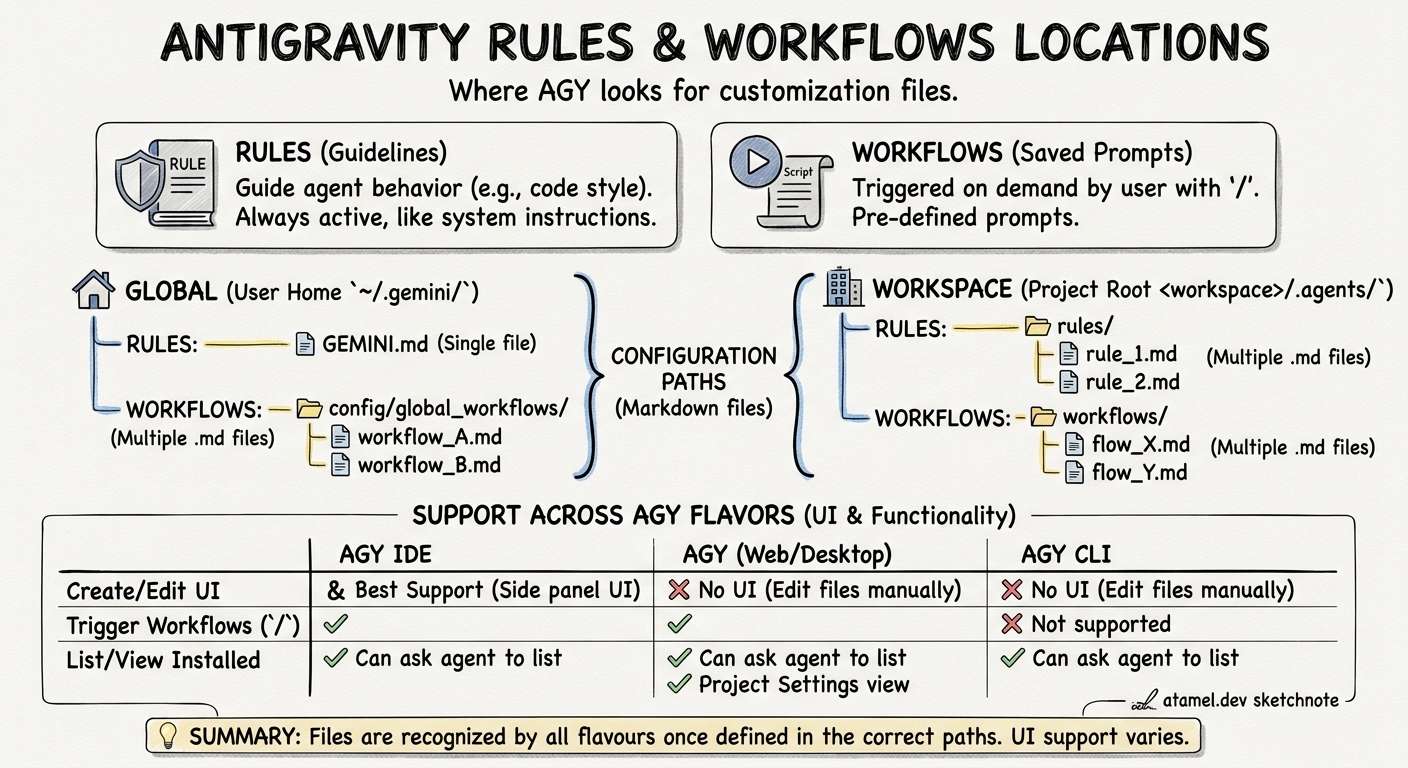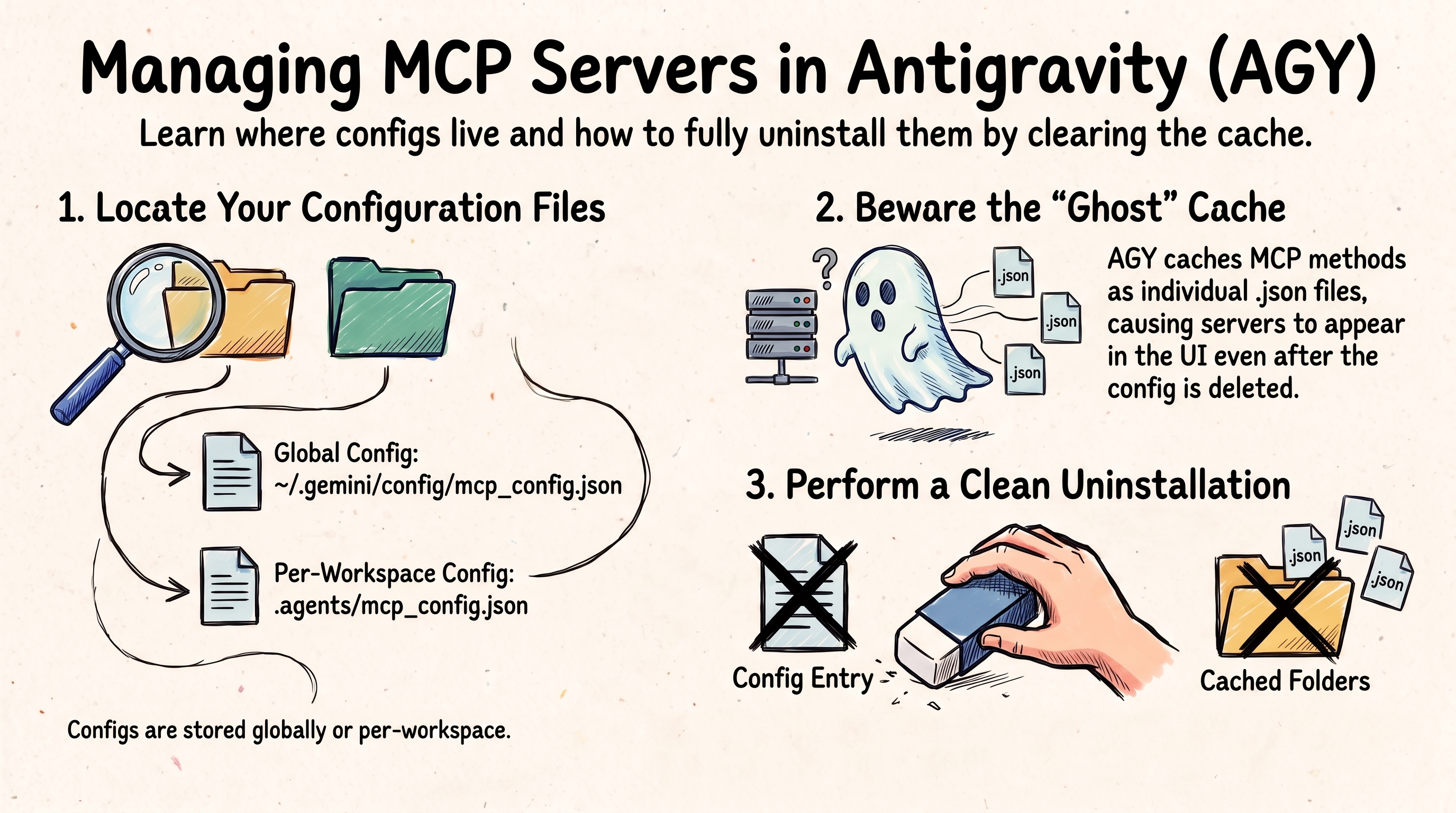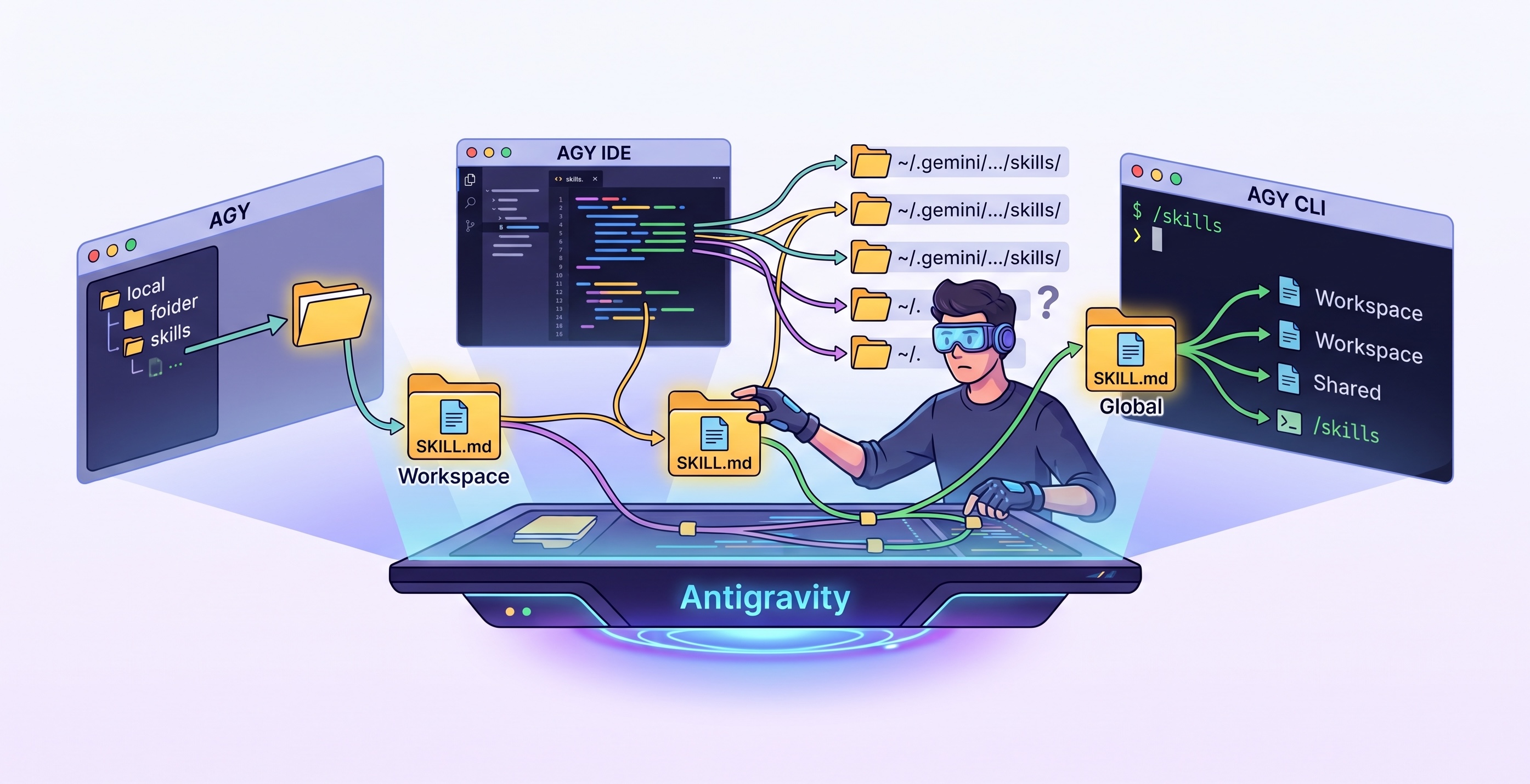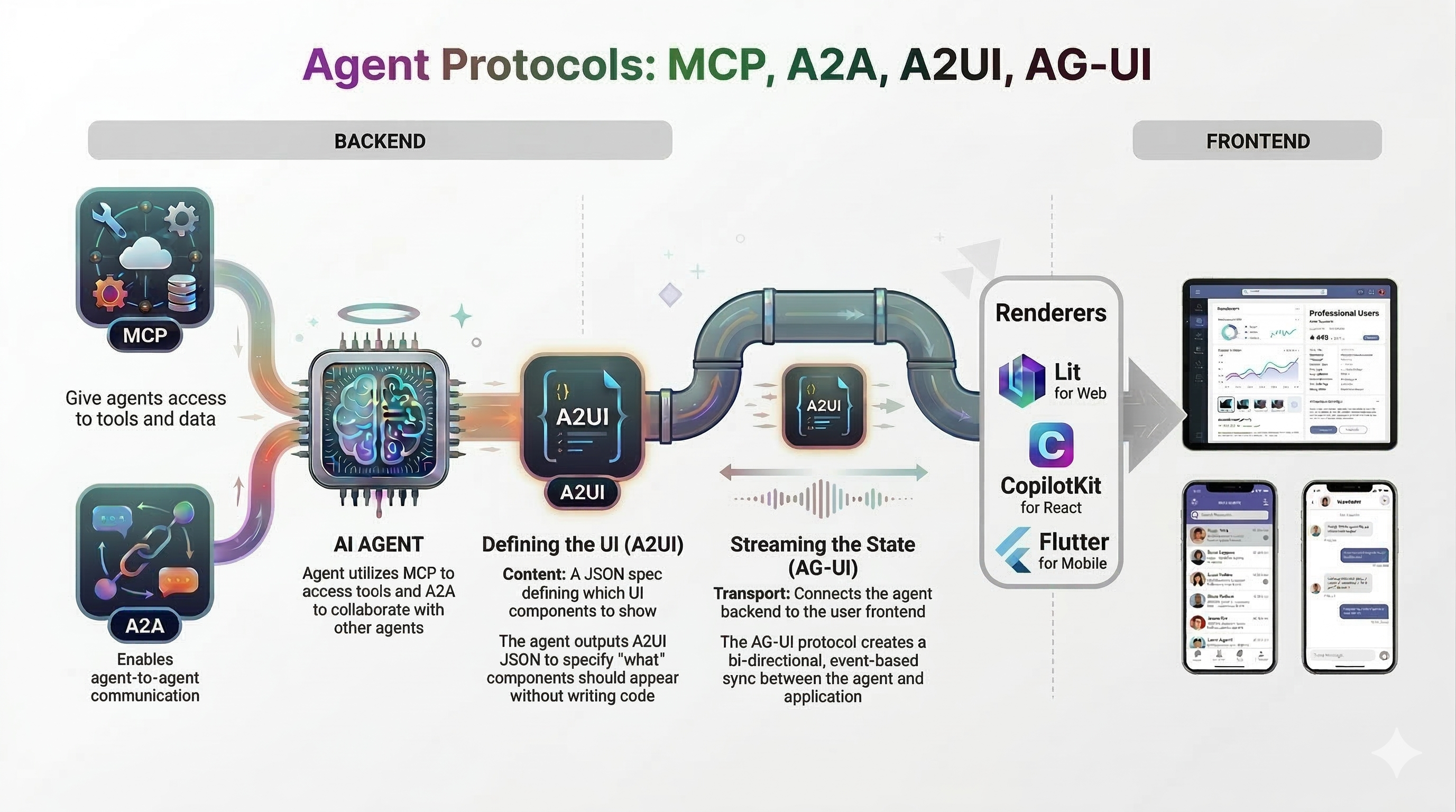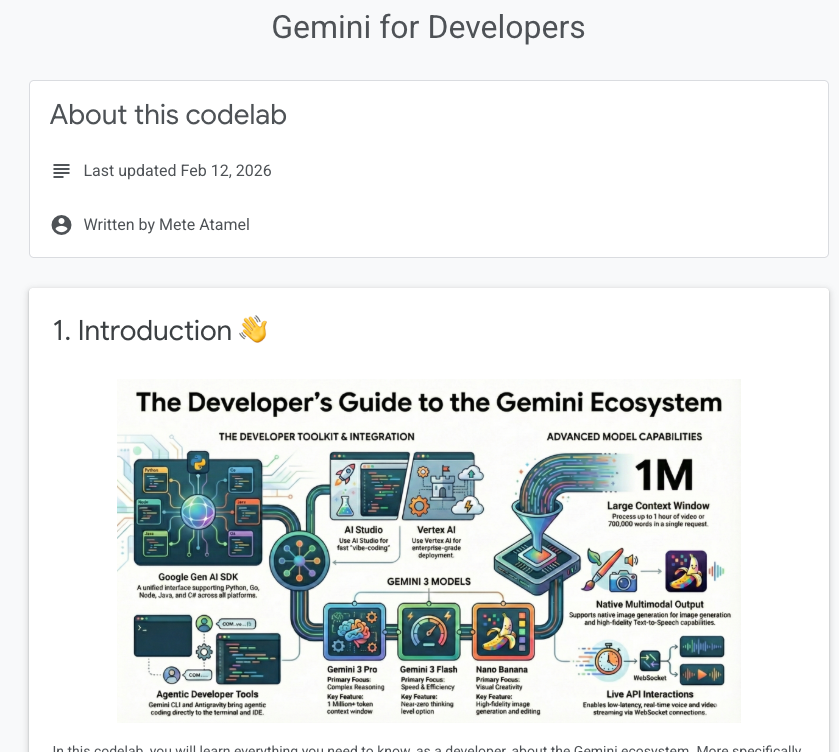
💡 This post is part of a series on Antigravity configuration:
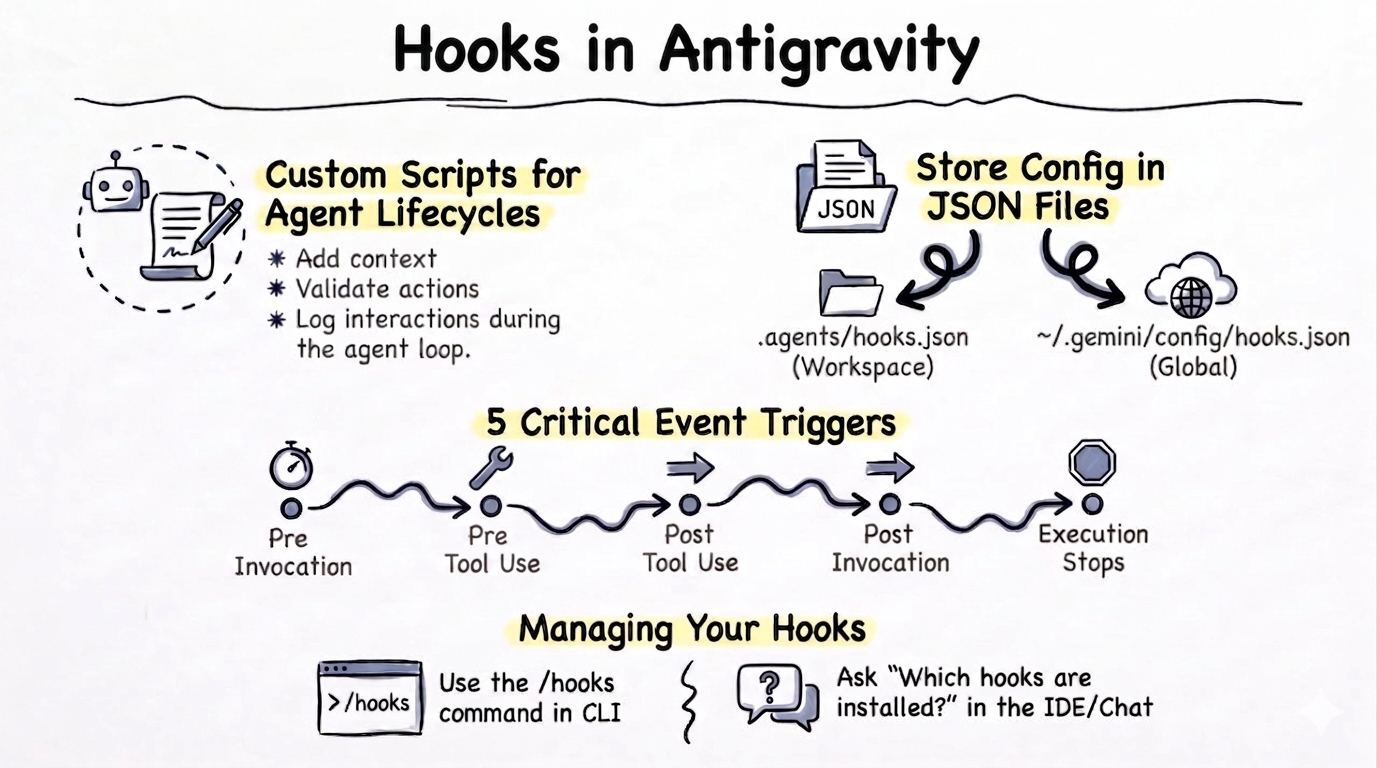
In today’s post, I’ll talk about Hooks in Antigravity, what they are, how to configure them, and some shortcomings.
Hooks
Hooks allow you to run custom scripts or programs at specific points in the Antigravity agent lifecycle, such as before or after model or tool calls. They are a way to extend the functionality of the agent. Hooks run synchronously as part of the agent loop and they can be useful for things like adding context, validating actions, enforce policies or logging interactions.
Read More →