In part 3 of the blog series, I talked about how we transformed our Windows-only .NET Framework app to a containerized multi-platform .NET Core app.
This removed our dependency on Windows and enabled us to deploy to Linux-based platforms such as App Engine (Flex). On the other hand, the app still ran on VMs, it was billed per second even if nobody used it, deployments were slow and most importantly, it was a single monolith that was deployed and scaled as a single unit.
In the last phase of modernization, I want to talk about how we transformed our monolith into a set of serverless microservices with Cloud Run and the benefits of that transformation.
Serverless with Cloud Run
After containerization of our app in early 2019, we wanted to run it in a managed/serverless platform, mainly to avoid VM pricing. However, Cloud Functions did not support C#/.NET as a runtime (and still does not) and that tied our hands until mid 2019.
In mid 2019, Cloud Run was announced at Google Cloud Next conference in San Francisco, as a new fully managed platform to run stateless containers. Our app was already stateless (all the state was in-memory) and it was already containerized, so Cloud Run was immediately a game changer for us.
After a quick update of our code to ASP.NET Core 3.0, we were able to deploy our container to Cloud Run with a single gcloud command. We essentially replaced App Engine with Cloud Run overnight:
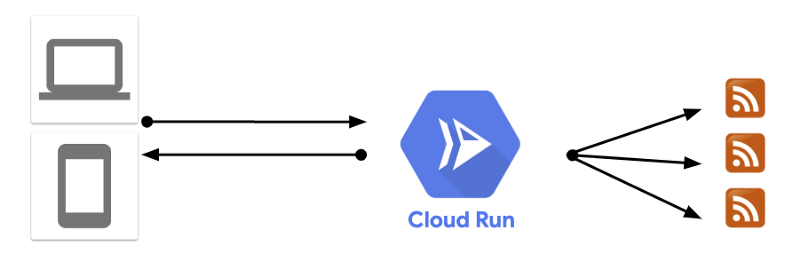
This might not look like a big change but it had immediate benefits:
- Pricing: We went from VM based pricing to Cloud Run pricing where you only pay for the request time. For a small and occasionally connected app like ours, the bill basically ended up being almost free (Cloud Run has a free tier).
- Deployment time: Our deployment time went from 5–10 minutes on App Engine to 3–5 seconds on Cloud Run. This enabled us to iterate much faster.
- DevEx: The developer experience on Cloud Run is awesome! We got metrics, logs displayed nicely in Cloud Run dashboard. We had features like revisions and traffic splitting from App Engine on Cloud Run.
- Based on open-source: It was also good to know that Cloud Run is based on Knative, an open source project. If we ever wanted to leave the managed Google Cloud environment, we could easily deploy the same app and get similar features with Knative on anywhere Kubernetes runs.
These were pretty quick wins with almost no effort.
Monolith issues
Despite the quick wins, Cloud Run also amplified the problems caused by the monolith nature of our app. Our app was composed of 3 services: reader, transformer and web frontend bundled and deployed together. This caused issues such as:
- Scaling: We typically needed 1 reader and 1 transformer and occasional scaling of web frontend. When we scaled, we scaled all 3 services and this was not necessary.
- Cold starts: Cloud Run automatically scales down your containers when not in use. This saves money but in our case, this was an issue because even the reader would be scaled down. When the container scaled up from zero, it would take some time for the reader to fetch feeds and populate in-memory state.
- In-memory state: All our state was in-memory. This wasn’t ideal after cold starts. We needed a more persistent storage at this stage.
- No ability to update individual services: We had to update transformer frequently because RSS feed formats changed quite often, whereas we didn’t have to update reader or web frontend that much. There was no way to pick and choose what to update.
All of these issues made it obvious that we had to finally decompose our monolith into separate services.
Monolith decomposition
Monolith decomposition sounds like a good idea in theory. In reality, it is quite difficult to do properly. There are many questions you need to answer:
- How do you break the monolith? Ideally, you have distinct enough functionality to make unique services obvious but it’s not always clear cut. Even if it’s clear cut, you probably need to do a lot of refactoring to realize it.
- How do microservices communicate? Once you replace function calls within the monolith with network calls between services, you need to think about how services communicate. Should it be sync or async calls? Should be it HTTP or some kind of Pub/Sub messaging? Either way, it’ll be harder than function calls. You need to make sure this is a price you want to pay.
- How do you handle persistency without coupling? You want your services to be as stateless as possible for many reasons but at some point, you need to save some data somewhere. One easy mistake to have multiple services depend on the same persistence layer. This would couple microservices not in code but in persistence and it defeats the purpose of decomposing in the first place.
There are many other considerations but you get the idea. Monolith decomposition is not as straightforward as you might think.
Final architecture
In the end, this is the architecture we ended up with:
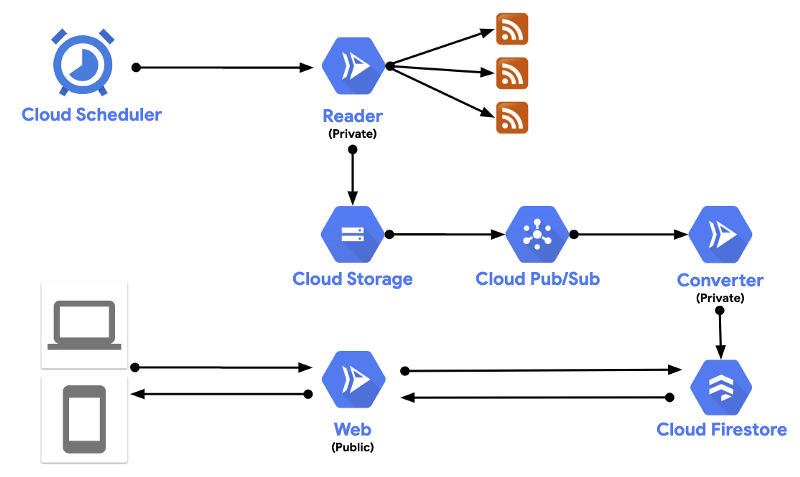
These 3 separate services: Reader, Converter, Web Frontend:
- Reader is an internal Cloud Run service that gets called by Cloud Scheduler on a set schedule. It fetches RSS feeds from a list of sources and stores them as json in Cloud Storage.
- Converter is another internal Cloud Run service. Once Reader saves RSS json in Cloud Storage, this triggers a message to a Pub/Sub topic and in turn, Pub/Sub calls the Converter service. Then, Converter uses pre-defined rules to transform different RSS feeds into a common format and saves to Cloud Firestore, a NoSQL database that is ideal for JSON like data.
- Web is a public Cloud Run service that simply exposes a Web API for the feed data saved in Cloud Firestore.
If you want to take a closer look at the code, it’s already on GitHub: https://github.com/meteatamel/amathus
The final architecture solved pretty much all the issues I outlined earlier. There are 3 focused services doing 1 thing at a time well. Each service can be independently reasoned about, updated and scaled. Updating is not scary anymore. It’s just an update to one of the services and the revision feature of Cloud Run makes reverting back to previous code very easy. There’s loose dependency between services via Pub/Sub and Firestore. No issue with cold starts as the Web frontend is backed with Firestore and it’s pretty quick to start up.
On the flip side, the architecture is considerably more complex than before. There are a few moving parts and overall setup is not as easy as a single Cloud Run service with no external dependencies. However, that’s the price we were willing to pay to make the architecture more resilient and easier to update.
This wraps up the 4 part blog series on our app modernization journey. Hope you enjoyed reading about our journey and if you have feedback or questions, feel free to reach out to me on Twitter @meteatamel