Retrieval-Augmented Generation (RAG) emerged as a dominant framework to feed LLMs the context beyond the scope of its training data and enable LLMs to respond with more grounded answers with less hallucinations based on that context.
However, designing an effective RAG pipeline can be challenging. You need to answer certain questions such as:
- How should you parse and chunk text documents for embedding? What chunk and overlay size to use?
- What embedding model is best for your use case?
- What retrieval method works most effectively? How many documents should you retrieve by default? Does the retriever actually manage to retrieve the relevant documents?
- Does the generator actually generate content in line with the relevant context? What parameters (e.g. model, prompt template, temperature) work better?
The only way to objectively answer these questions is to measure how well the RAG pipeline works but what exactly do you measure? This is the topic of this blog post.
Typical RAG pipeline
A typical RAG pipeline is made up of two separate pieces: retriever and generator.
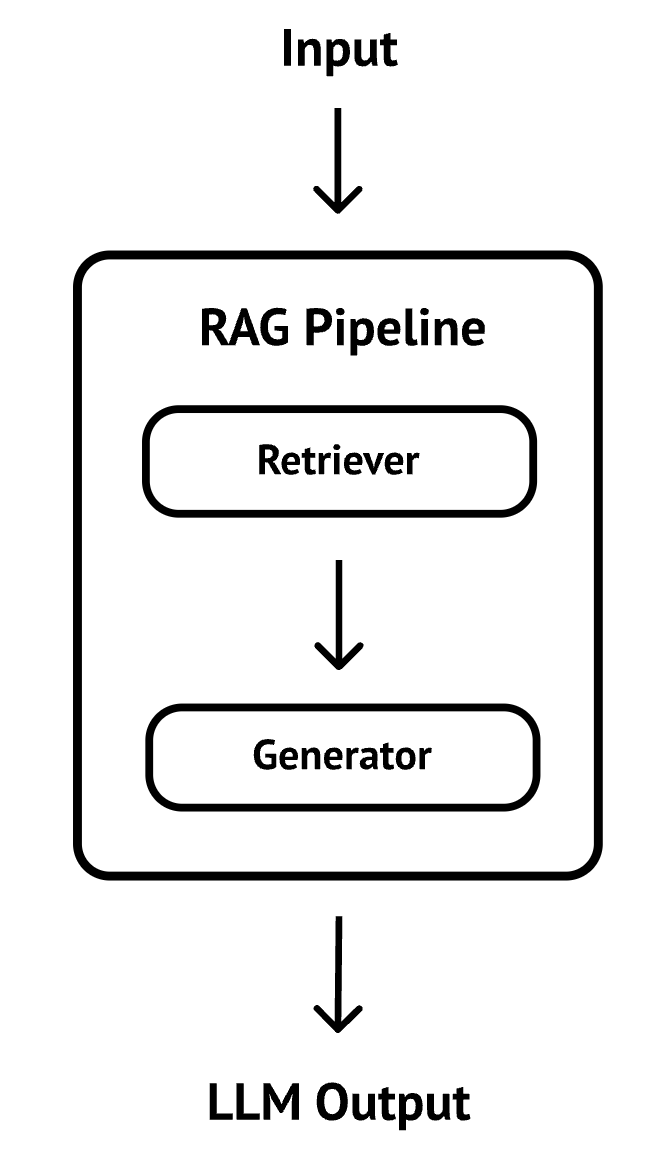
Retriever is responsible for embedding the text chunks into a vector database and later performing similarity searches against them.
Generator is responsible for generating content based on the supplied context by the retriever and other parameters such as model, prompt template, temperature.
I’ve seen two approaches in measuring the effectiveness of the RAG pipeline.
Approach 1: Evaluating Retrieval and Generator separately
In this approach, you evaluate the retriever and generator of the RAG pipeline separately using their separate metrics:
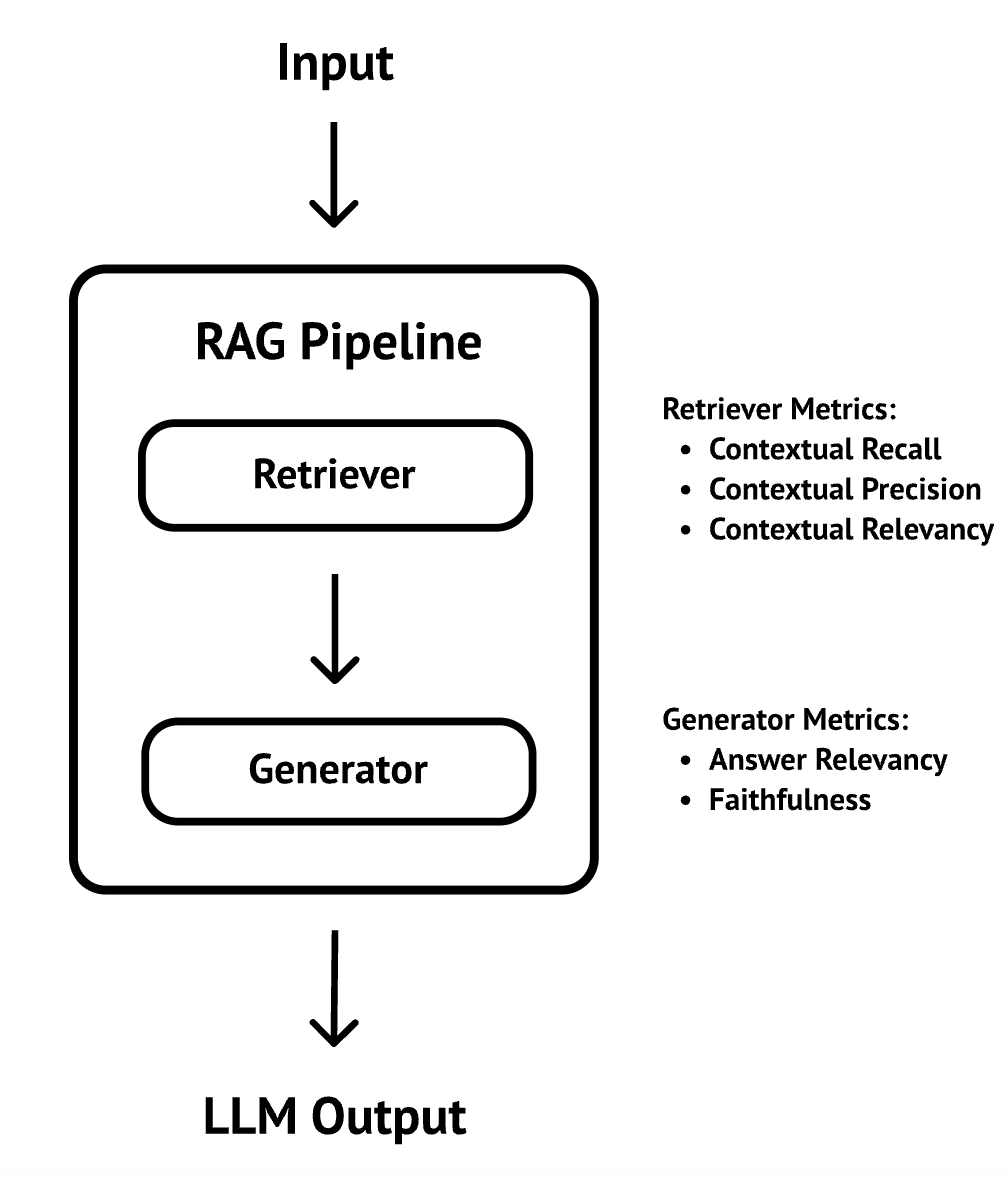
For the retriever, these are the metrics:
- Contextual Relevance evaluates the overall relevance of the retrieved context for a given input.
- Contextual Recall evaluates how well the retrieved context aligns with the expected output.
- Contextual Precision evaluates whether nodes in the retrieved context that are relevant to the given input are ranked higher than irrelevant ones.
For the generator, these are the metrics:
- Faithfulness / Groundedness evaluates whether the actual output factually aligns with the retrieved context.
- Answer relevancy evaluates how relevant the actual output is to the provided input.
This approach allows pinpoint issues on a retriever or generator level. You can determine whether the retriever is failing to retrieve the correct and relevant context or whether the generator is hallucinating despite being provided the right context.
On the other hand, both contextual recall and contextual precision require an expected output (the ideal answer to a user input) to compare against. This might not be possible to determine upfront. That’s why the RAG triad emerged as the alternative referenceless RAG evaluation method.
Approach 2: RAG Triad
The RAG triad is composed of three RAG evaluation metrics: answer relevancy, faithfulness, and contextual relevance.
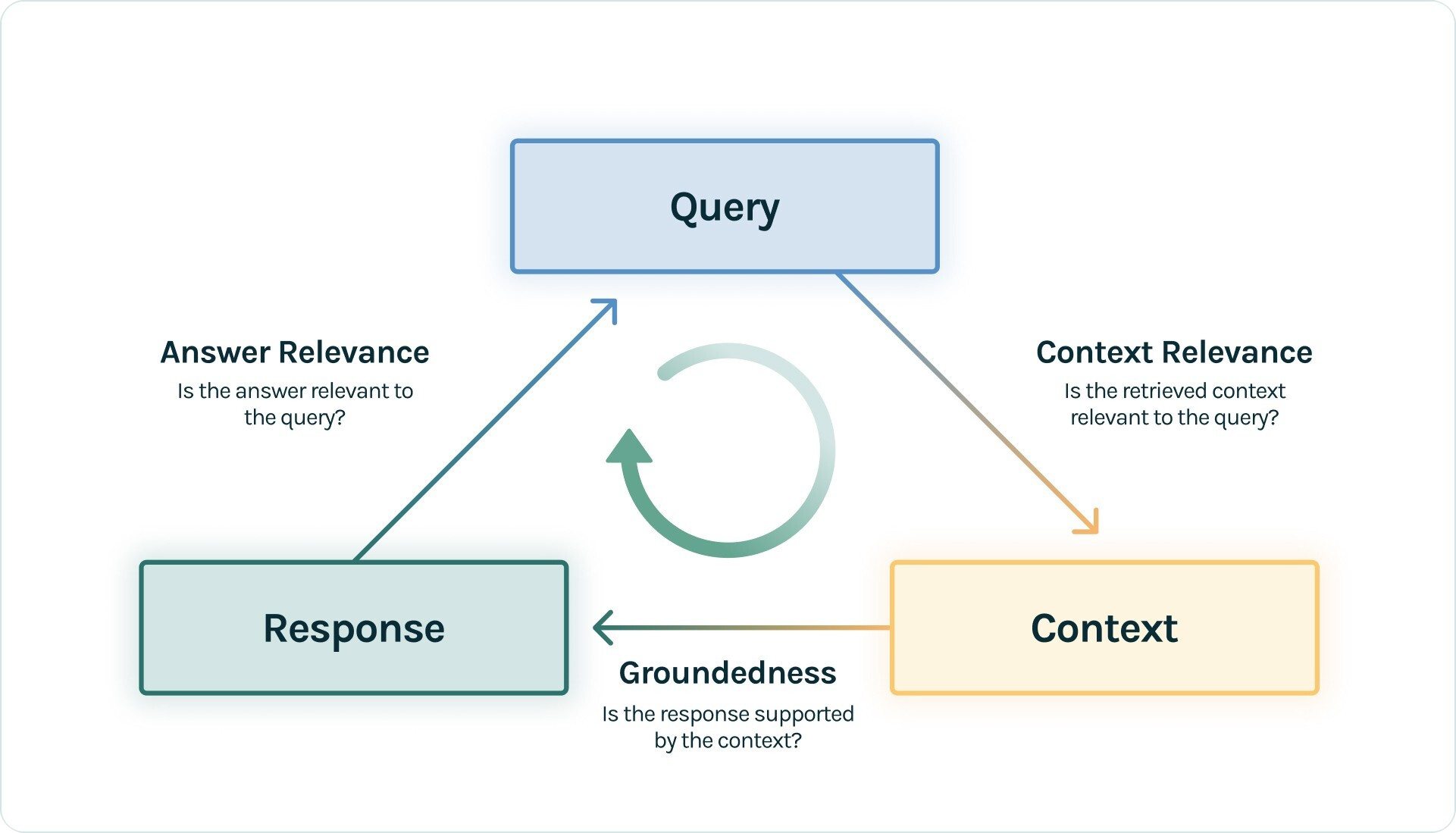
We already defined these metrics but let’s see what low scores in each metric means:
- Contextual Relevance: If this score is low, it usually points to a problem in how the text is chunked, embedded, and retrieved. This concerns the chunk size, top-K and embedding model.
- Faithfulness / Groundedness: If this score is low, it usually points to a problem in your model. Maybe you need to try a better model or fine-tune your own model to get more grounded answers based on the retrieved context.
- Answer relevancy: If this score is low, it usually points to a problem in your prompt. Maybe you need better prompt templates or better examples in your prompts to get more relevant answers.
One thing to point out is that since contextu precision and context recall are not part of the RAG triad, this allows evaluations without expected outputs.
Other Metrics
There are other metrics you can consider for RAG evaluation depending on the framework you’re using. For example, these are some additional metrics from Ragas framework:
- Context Entities Recall
- Noise Sensitivity
- Multimodal Faithfulness
- Multimodal Relavance
- BLEU Score
- ROUGE Score
- Tool call accuracy
However, it’s best to start with something simple like the RAG triad and add on more precise metrics as you determine you need them for a specific reason.
Frameworks
In my research, I came across a few frameworks that can help with RAG evaluation:
- DeepEval has been my go-to LLM evaluation framework and they have the metrics needed for the RAG triad along with a RAG triad guide.
- TruLens is another LLM evaluation framework with a RAG triad guide.
- Ragas has an extensive list of metrics that can be used for the RAG triad.
Do you know any other frameworks? If so, let me know!
Conclusion
In this blog post, I explored a couple of different approaches to evaluating RAG pipelines and what metrics to use. In the next post, I’ll see what it takes to implement the RAG triad with one of the frameworks.
References:
- DeepEval: RAG Evaluation
- DeepEval: Using the RAG Triad for RAG evaluation
- TruLens: The RAG triad
- Ragas metrics