In my previous RAG Evaluation - A Step-by-Step Guide with DeepEval post, I showed how to evaluate a RAG pipeline with the RAG triad metrics using DeepEval and Vertex AI. As a recap, these were the results:
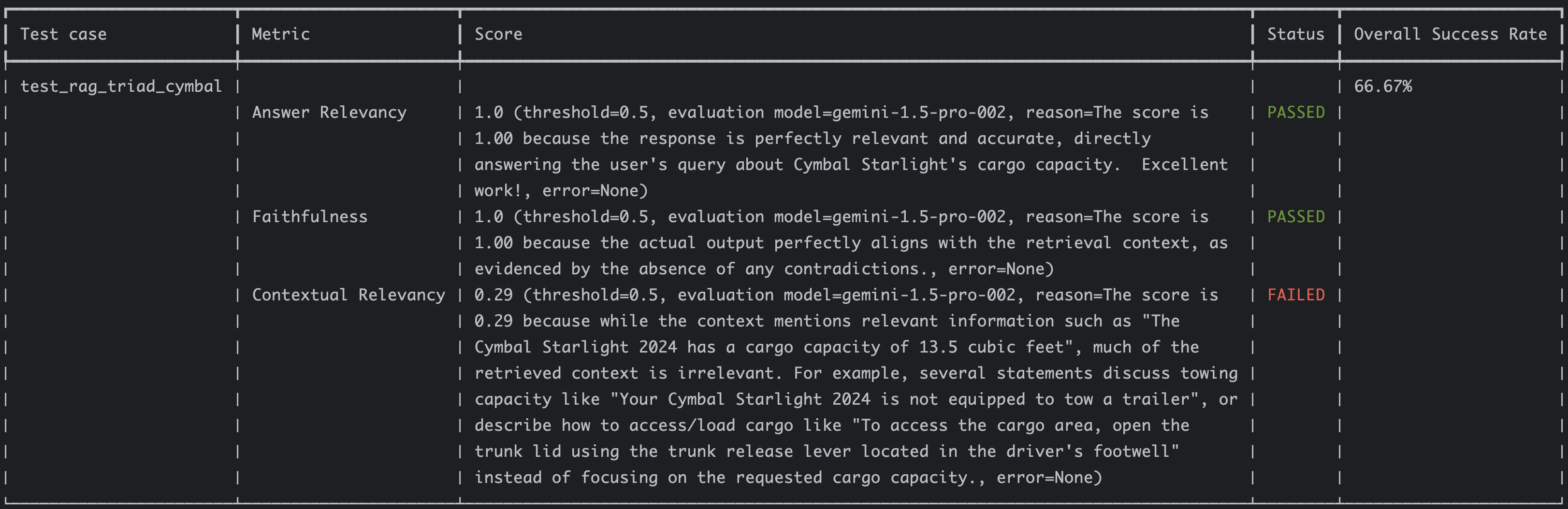
Answer relevancy and faithfulness metrics had perfect 1.0 scores whereas contextual relevancy was low at 0.29 because we retrieved a lot of irrelevant context:
The score is 0.29 because while the context mentions relevant information such as "The Cymbal Starlight 2024 has a cargo
capacity of 13.5 cubic feet", much of the retrieved context is irrelevant. For example, several statements discuss
towing capacity like "Your Cymbal Starlight 2024 is not equipped to tow a trailer", or describe how to access/load cargo
like "To access the cargo area, open the trunk lid using the trunk release lever located in the driver's footwell"
instead of focusing on the requested cargo capacity.
Can we improve this? Let’s take a look.
Important: Since we’re using another LLM (gemini-1.5-pro-002 in this case) to evaluate the RAG
pipeline, these scores will not be stable. Sometimes you’ll get 0.29, sometimes 0.27 or 0.32. This is due to LLM
randomness and it’s OK. We’re not looking for strict numbers but rather an upward trajectory.
Parameters to improve
In
test_rag_triad.py
and its helper
utils.py
where we set up the RAG pipeline, there are a few parameters that we can tweak such as the embedding model, chunk size,
chunk overlap, prompt and temperature:
PDF_PATH = "cymbal-starlight-2024.pdf"
EMBEDDING_MODEL_NAME = "textembedding-gecko@003"
CHUNK_SIZE = 500
CHUNK_OVERLAP = 100
SYSTEM_PROMPT = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer
the question. If you don't know the answer, say that you
don't know. Use three sentences maximum and keep the
answer concise."""
MODEL_NAME="gemini-1.5-flash-002"
TEMPERATURE=1
Let’s go through some of them and see if they can improve the contextual relevancy metric.
Embedding model
Embedding models plays a major role on how the text is embedded and retrieved. We’re currently using
textembedding-gecko@003. In the Text embedding API docs
page for Vertex AI, we can
see different embedding models:
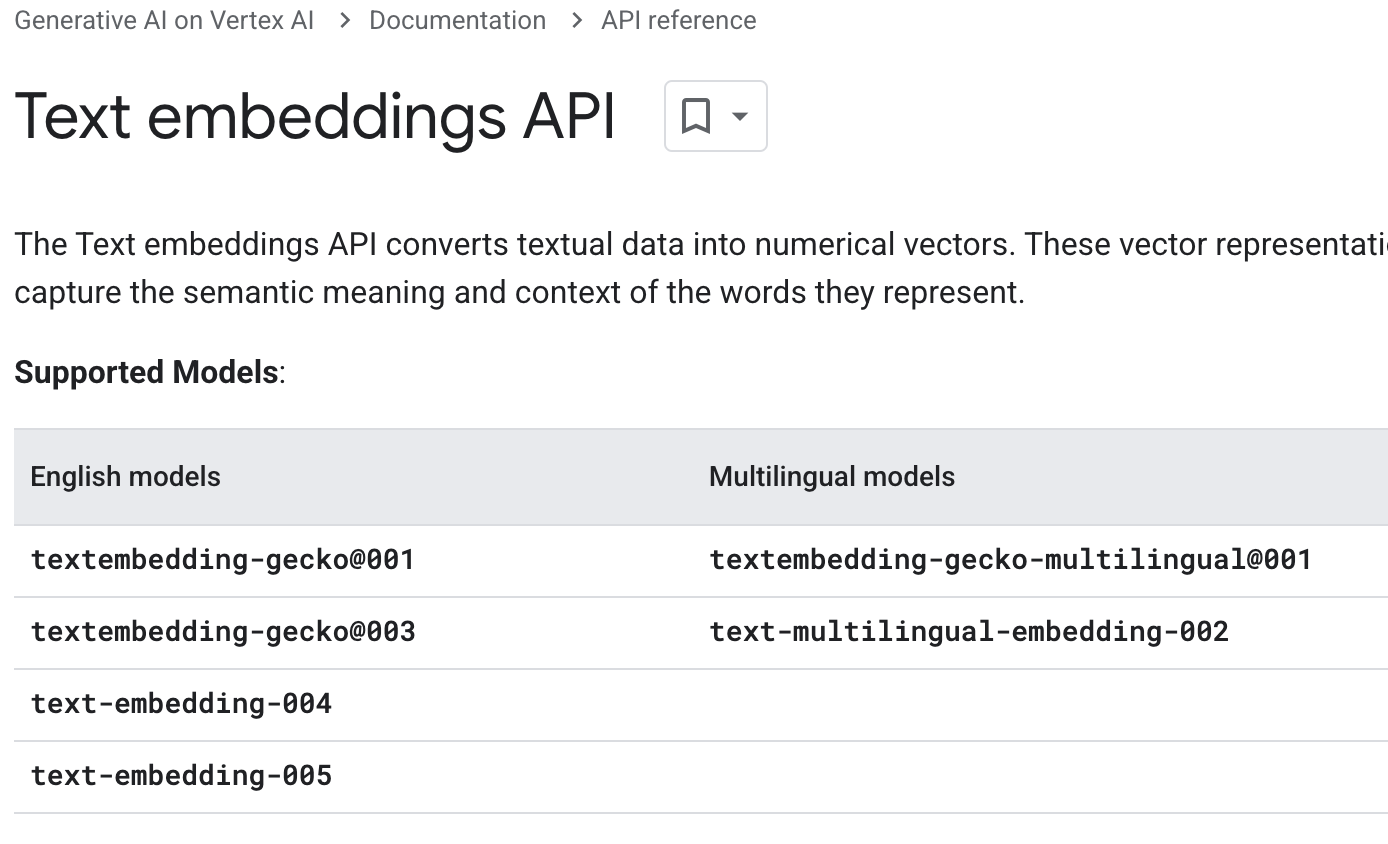
Let’s change the embedding model to text-embedding-005:
EMBEDDING_MODEL_NAME_1 = "textembedding-gecko@003"
EMBEDDING_MODEL_NAME_2 = "text-embedding-005"
EMBEDDING_MODEL_NAME = EMBEDDING_MODEL_NAME_2
Run the evaluation again:
deepeval test run test_rag_triad_cymbal.py
You’ll get a similar contextual relevancy score with a similar reason. Looks like the embedding model is not making a difference here.
Chunk size and overlap
We initially chose a chunk size of 500 with an overlap of 100 characters for chunking and embedding text with no good reason. Maybe the chunk size is contributing to the irrelevant context and do we even need an overlap?
Let’s change these values to 100 and 0 respectively:
CHUNK_SIZE_1 = 500
CHUNK_SIZE_2 = 200
CHUNK_SIZE = CHUNK_SIZE_2
CHUNK_OVERLAP_1 = 100
CHUNK_OVERLAP_2 = 0
CHUNK_OVERLAP = CHUNK_OVERLAP_2
Run the evaluation again:
deepeval test run test_rag_triad_cymbal.py
This time the score slightly improved to 0.3 but the same reason is given for the low score (lots of irrelevant context).
Number of documents
If we take a look at the retrieved context, you can see that we’re retrieving 4 documents, this is the default in LangChain but only the first one is really relevant to the question:
Retrieval context: [
'Your Cymbal Starlight 2024 is not equipped to tow a trailer.\nCargo\nThe Cymbal Starlight 2024
has a cargo capacity of 13.5 cubic feet. The cargo area is located in the trunk of\nthe vehicle.',
'The Cymbal Starlight 2024 can accommodate up to two suitcases in the trunk. When packing luggage,
be\nsure to use soft-sided luggage to maximize space.',
'By following these tips, you can safely and conveniently transport cargo and luggage in your
Cymbal\nStarlight 2024.\n Chapter 7: Driving Procedures with Automatic Transmission\nStarting the Engine',
'The fuel tank in your Cymbal Starlight 2024 has a capacity of 14.5 gallons.\nRefueling Procedure\n
To refuel your Cymbal Starlight 2024, follow these steps:\n\x00. Park your vehicle on a level surface.']
We can try to only retrieve 1 most relevant document and see if that helps:
#retriever = vector_store.as_retriever()
retriever = vector_store.as_retriever(search_kwargs={"k": 1})
Run the evaluation again:
deepeval test run test_rag_triad_cymbal.py
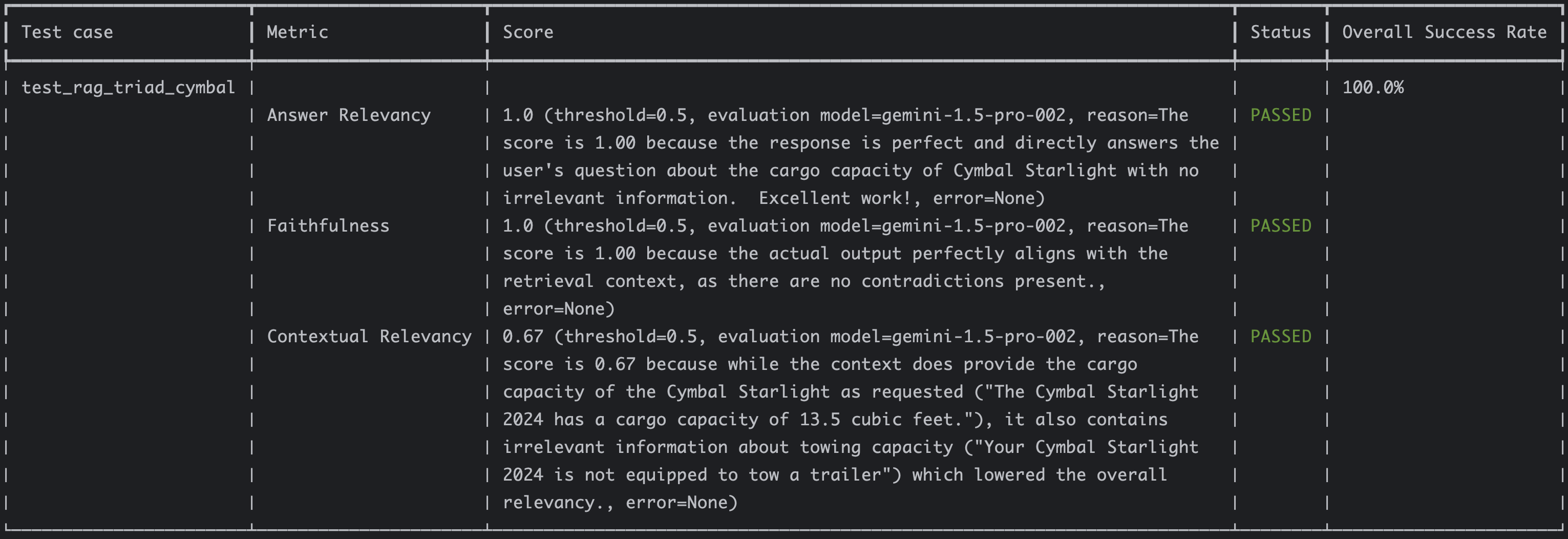
We can see that the retrieved context is only one document:
Retrieval context: ['Your Cymbal Starlight 2024 is not equipped to tow a trailer.\nCargo\n
The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet.
The cargo area is located in the trunk of\nthe vehicle.']
The contextual relevancy score jumped to 0.67 without affecting other scores:
Build an evaluation suite
We made some progress in improving the RAG triad scores but this has only been for 1 question (What is the cargo capacity of Cymbal Starlight?). We don’t want to over optimize for one question. We really need an evaluation suite with
a list of questions. This is quite easy to do with DeepEval.
First, you set up the RAG chain and define the list of questions you want to test with:
CHAT_MODEL_STR = "gemini-1.5-flash-002"
EVAL_MODEL_NAME = "gemini-1.5-pro-002"
def test_rag_triad_cymbal_multiple():
rag_chain = setup_rag_chain()
inputs = [
"What is the cargo capacity of Cymbal Starlight?",
"Is there a tire repair kit in Cymbal Starlight?",
"What's the emergency roadside assistance number for Cymbal?"
]
Then, you invoke the RAG chain for each question, get the output and the retrieval context, and create an LLMTestCase
out of them:
test_cases = []
for input in inputs:
print(f"Input: {input}")
print("Invoking RAG chain")
response = rag_chain.invoke({"input": input})
output = response['answer']
print(f"Output: {output}")
retrieval_context = [doc.page_content for doc in response['context']]
print(f"Retrieval context: {retrieval_context}")
test_case = LLMTestCase(
input=input,
actual_output=output,
retrieval_context=retrieval_context
)
test_cases.append(test_case)
In the final step, you create your RAG triad metrics and pass the test cases with the metrics to the evaluate method. This will run these test cases in parallel:
print(f"Evaluating with model: {EVAL_MODEL_NAME}")
eval_model = GoogleVertexAI(model_name=EVAL_MODEL_NAME,
project=get_project_id(),
location="us-central1")
metrics = [
AnswerRelevancyMetric(model=eval_model),
FaithfulnessMetric(model=eval_model),
ContextualRelevancyMetric(model=eval_model)
]
evaluation_result = evaluate(test_cases=test_cases, metrics=metrics)
The full sample is in
test_rag_triad_cymbal_multiple.py.
Run the evaluation:
deepeval test run test_rag_triad__cymbal_multiple.py
You get the results for all:
Metrics Summary
- ✅ Answer Relevancy (score: 1.0, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 1.00 because the response is perfect! It directly and accurately answers the user's question about Cymbal's emergency roadside assistance number, without any unnecessary information. Keep up the great work!, error: None)
- ✅ Faithfulness (score: 1.0, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 1.00 because the output aligns perfectly with the retrieval context, as there are no contradictions present., error: None)
- ✅ Contextual Relevancy (score: 1.0, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 1.00 because the context contains all the necessary information to answer the question, directly stating both that Cymbal offers roadside assistance and providing the correct number '1-800-555-1212'., error: None)
For test case:
- input: What's the emergency roadside assistance number for Cymbal?
- actual output: The emergency roadside assistance number for Cymbal Starlight 2024 is 1-800-555-1212. This service is available 24/7.
- expected output: None
- context: None
- retrieval context: ['Your Cymbal Starlight 2024 comes with 24/7 emergency roadside assistance.\nTo contact emergency roadside assistance, call the following number: 1-800-555-1212.']
======================================================================
Metrics Summary
- ✅ Answer Relevancy (score: 1.0, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 1.00 because the response is perfectly relevant and helpful, directly addressing the user's query about the tire repair kit in the Cymbal Starlight travel trailer. Keep up the great work!, error: None)
- ✅ Faithfulness (score: 1.0, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 1.00 because the output is completely faithful to the provided context, with no contradictions whatsoever! Excellent job!, error: None)
- ✅ Contextual Relevancy (score: 1.0, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 1.00 because the retrieved context directly answers the user's question about the presence and location of a tire repair kit in the Cymbal Starlight, as evidenced by the statements: 'Your Cymbal Starlight 2024 comes with a tire repair kit...' and 'The tire repair kit is located in the trunk...'. Perfect!, error: None)
For test case:
- input: Is there a tire repair kit in Cymbal Starlight?
- actual output: Yes, the Cymbal Starlight 2024 includes a tire repair kit for temporary flat tire fixes. It's located in the vehicle's trunk.
- expected output: None
- context: None
- retrieval context: ['Tire Repair Kit\nYour Cymbal Starlight 2024 comes with a tire repair kit that can be used to temporarily repair a flat\ntire.\nThe tire repair kit is located in the trunk of the vehicle.']
======================================================================
Metrics Summary
- ✅ Answer Relevancy (score: 1.0, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 1.00 because the response is completely relevant and accurate, directly addressing the user's query about the cargo capacity of Cymbal Starlight. Keep up the great work!, error: None)
- ✅ Faithfulness (score: 1.0, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 1.00 because the output perfectly aligns with the provided context, as evidenced by the absence of any contradictions., error: None)
- ✅ Contextual Relevancy (score: 0.6666666666666666, threshold: 0.5, strict: False, evaluation model: gemini-1.5-pro-002, reason: The score is 0.67 because while the context does provide the cargo capacity of the Cymbal Starlight as requested ("The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet."), it also includes information about towing capacity ("Your Cymbal Starlight 2024 is not equipped to tow a trailer") which is irrelevant to cargo space. This inclusion of irrelevant information lowers the overall relevancy score., error: None)
For test case:
- input: What is the cargo capacity of Cymbal Starlight?
- actual output: The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. This cargo area is located in the vehicle's trunk.
- expected output: None
- context: None
- retrieval context: ['Your Cymbal Starlight 2024 is not equipped to tow a trailer.\nCargo\nThe Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. The cargo area is located in the trunk of\nthe vehicle.']
Overall, those are pretty good results with almost perfect scores for all 3 RAG triad metrics.
At this point, you’d come up with more questions and iterate on other metrics such as temperature, system prompt, or chat model name but I’ll leave that as an exercise for you.
Conclusion
In this 3 part blog series, I showed you what metrics to use for RAG evaluation, how to implement RAG triad with DeepEval, and how to iterate and improve the RAG pipeline with RAG triad. There are many metrics you can use to evaluate and improve your RAG pipelines but RAG triad is a good start.
References:
- Part 1: Evaluating RAG pipelines
- Part 2: RAG Evaluation - A Step-by-Step Guide with DeepEval
- RAG eval samples
- DeepEval: RAG Evaluation
- DeepEval: Using the RAG Triad for RAG evaluation
- TruLens: The RAG triad
- Ragas metrics