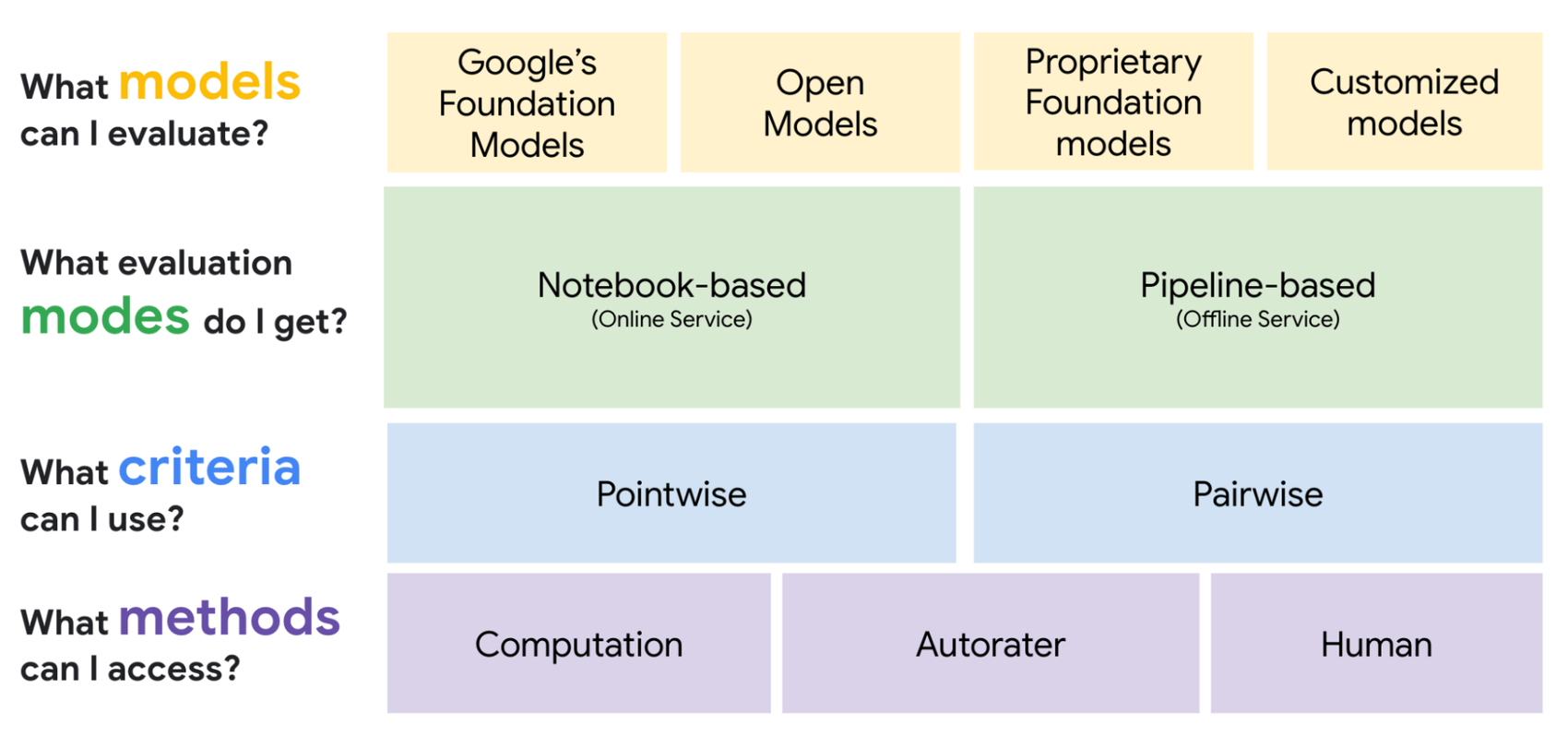
In the Gen AI Evaluation Service - An Overview post, I introduced Vertex AI’s Gen AI evaluation service and talked about the various classes of metrics it supports. In the Gen AI Evaluation Service - Computation-Based Metrics post, we delved into computation-based metrics, what they provide, and discussed their limitations. In today’s third post of the series, we’ll dive into model-based metrics.
The idea of model-based metrics is to use a judge model to evaluate the output of a candidate model. Using an LLM as a judge allows more flexible and rich evaluations that the computational/statistical metrics fail to do.
While you might question using an LLM as a judge, according to the Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena paper, LLMs are pretty good evaluators when used with good evaluation prompts and rubrics, and have 80% agreement with human evaluations—the same level of agreement seen between humans.
Let’s take a look at what kind of model-based metrics the Gen AI evaluation service provides.
List of metrics
There are two classes of model-based metrics in Gen AI evaluation service.
First, metrics used specifically for translation related tasks. Comet and MetricX are the supported translation metrics:
cometmetricx
Second, more generic metrics where the judge model evaluates a candidate model on various metrics such as fluency, safety, and so on. These are the metrics that come out of the box with the pre-built metric prompt templates:
coherenceandpairwise_coherencefluencyandpairwise_fluencysafetyandpairwise_safetygroundednessandpairwise_groundednessinstruction_followingandpairwise_instruction_followingverbosityandpairwise_verbositytext_qualityandpairwise_text_qualitysummarization_qualityandpairwise_summarization_qualityquestion_answering_qualityandpairwise_question_answering_qualitymulti_turn_chat_qualityandpairwise_multi_turn_chat_qualitymulti_turn_safetyandpairwise_multi_turn_safety
Each metric has pointwise (evaluating a single model) and pairwise (comparing two models) flavors.
If these metrics are not enough, you can also define your own metrics with a custom metric prompt template or even have a free-form metric prompt (more on this later).
Translation metrics
Translation metrics are pretty straightforward to use. See
translation.py
for details.
Run the evaluation:
python translation.py
After a few seconds, you should see the results:
==Summary metrics==
row_count: 2
comet/mean: 0.90514195
comet/std: 0.09416372713647334
metricx/mean: 3.5140458499999996
metricx/std: 0.6293740377559635
==Metrics table==
source response reference comet/score metricx/score
0 Dem Feuer konnte Einhalt geboten werden The fire could be stopped They were able to control the fire. 0.838558 3.069011
1 Schulen und Kindergärten wurden eröffnet. Schools and kindergartens were open Schools and kindergartens opened 0.971726 3.959080
Pointwise metrics
In pointwise metrics, you evaluate a single model. There are 2 ways of using pointwise metrics:
- Bring your own response (BYOR) mode where the model responses are saved from the previous runs of the model and provided as input to the evaluation (instead of calling the model during evaluation).
- Bring a model mode where you call the model and get responses during evaluation.
If BYOR mode, you provide the responses in the evaluation dataset. Here’s an example:
responses = [
"Clean-up operations are continuing across the Scottish Borders and Dumfries and Galloway after flooding caused by Storm Frank.",
"Two tourist buses have been destroyed by fire in a suspected arson attack in Belfast city centre.",
"Lewis Hamilton stormed to pole position at the Bahrain Grand Prix ahead of Mercedes team-mate Nico Rosberg.",
"Manchester City midfielder Ilkay Gundogan says it has been mentally tough to overcome a third major injury.",
]
eval_dataset["response"] = responses
In the model mode, you define a model and use that during evaluation to get responses:
model=GenerativeModel("gemini-2.0-flash")
eval_result = eval_task.evaluate(
model=model
)
See pointwise.py for details on how to define both types of pointwise metrics.
Run the evaluation in byor or model mode:
python pointwise.py byor
python pointwise.py model
After a few seconds, you should see the results:
==Summary metrics==
row_count: 4
fluency/mean: 3.25
fluency/std: 1.707825127659933
==Metrics table==
prompt response fluency/explanation fluency/score
0 Summarize the following article: The full cost... Clean-up operations are continuing across the ... The response provides very little information ... 1.0
1 Summarize the following article: A fire alarm ... Two tourist buses have been destroyed by fire ... The response is fluent, with no grammatical er... 5.0
2 Summarize the following article: Ferrari appea... Lewis Hamilton stormed to pole position at the... The response is mostly fluent, with clear word... 4.0
3 Summarize the following article: Gundogan, 26,... Manchester City midfielder Ilkay Gundogan says... The response is short and grammatical, but it ... 3.0
Pairwise metrics
If you want to compare two models, you can use pairwise metrics.
You first define a baseline model with the metric:
baseline_model = GenerativeModel("gemini-1.5-pro")
metric = PairwiseMetric(
metric=Metric.PAIRWISE_FLUENCY,
metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template(Metric.PAIRWISE_FLUENCY),
baseline_model=baseline_model
)
Then, you define another model to compare against and use that in the evaluation:
model=GenerativeModel("gemini-2.0-flash")
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[metric],
experiment=get_experiment_name(__file__),
)
eval_result = eval_task.evaluate(
model=model
)
See pairwise.py for details.
Run the evaluation:
python pairwise.py
After a few seconds, you should see the results where the two models are compared and a winner model is selected:
==Summary metrics==
row_count: 4
pairwise_fluency/candidate_model_win_rate: 0.0
pairwise_fluency/baseline_model_win_rate: 1.0
==Metrics table==
prompt response ... pairwise_fluency/explanation pairwise_fluency/pairwise_choice
0 Summarize the following article: The full cost... Severe flooding has impacted several areas in ... ... BASELINE response is slightly more fluent due ... BASELINE
1 Summarize the following article: A fire alarm ... In the early hours of Saturday, a fire alarm a... ... Both responses are well-written and follow the... BASELINE
2 Summarize the following article: Ferrari appea... Lewis Hamilton secured pole position for the B... ... BASELINE response has slightly better writing ... BASELINE
3 Summarize the following article: Gundogan, 26,... Ilkay Gundogan is recovering from a torn cruci... ... BASELINE response has a slightly better flow a... BASELINE
Custom metrics
If the metrics defined in the pre-built metric prompt templates are not good for your use case, you can define your own prompts for custom metrics. You can do this with a metric prompt template or define a free-form metric prompt for full flexibility.
Here’s an example of defining a custom metric with custom criteria with the template:
# Define a pointwise metric with two criteria
custom_metric_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"one_sentence": (
"The response is one short sentence."
),
"entertaining": (
"The response is entertaining."
),
},
rating_rubric={
"3": "The response performs well on both criteria.",
"2": "The response performs well with only one of the criteria.",
"1": "The response falls short on both criteria",
},
)
Or you can write your own prompt in free-form:
custom_metric_prompt_template = """
# Instruction
You are an expert evaluator. Your task is to evaluate the quality of the responses generated by AI models. We will provide you with the user prompt and an AI-generated responses.
You should first read the user input carefully for analyzing the task, and then evaluate the quality of the responses based on the Criteria provided in the Evaluation section below.
You will assign the response a rating following the Rating Rubric and Evaluation Steps. Give step by step explanations for your rating, and only choose ratings from the Rating Rubric.
# Evaluation
## Criteria
entertaining: The response is entertaining.
one_sentence: The response is one short sentence.
## Rating Rubric
1: The response falls short on both criteria
2: The response performs well with only one of the criteria.
3: The response performs well on both criteria.
## Evaluation Steps
Step 1: Assess the response in aspects of all criteria provided. Provide assessment according to each criterion.
Step 2: Score based on the rating rubric. Give a brief rationale to explain your evaluation considering each individual criterion.
# User Inputs and AI-generated Response
## User Inputs
## AI-generated Response
{response}
"""
Then, use the custom prompt template in your metric:
custom_metric = PointwiseMetric(
metric="custom_metric",
metric_prompt_template=custom_metric_prompt_template
)
See pointwise_custom_metric.py for details.
Implementing the RAG triad with custom metrics
Let’s finish up by showing an example on how flexible the Gen AI evaluation service can be.
In my previous blog posts, I talked about the RAG triad metrics (answer relevance, context relevance, groundedness) to measure effectiveness of your Retrieval Augmented Generation (RAG) pipeline.

While the Gen AI evaluation service does not have RAG triad built in, you can define these metrics with a rubric quite easily and combine them into a RAG triad metric.
Here’s how you’d define the answer relevance metric:
answer_relevance_metric = PointwiseMetric(
metric="answer_relevance",
metric_prompt_template=PointwiseMetricPromptTemplate(
criteria={
"answer_relevance": (
"Only check response and prompt. Ignore context. Is the response relevant to the prompt?"
),
},
metric_definition="Answer relevance: Checks to see if the response is relevant to the prompt",
rating_rubric={
"4": "The response is totally relevant to the prompt",
"3": "The response is somewhat relevant to the prompt",
"2": "The response is somewhat irrelevant to the prompt",
"1": "The response is totally irrelevant to the prompt",
},
input_variables=["prompt"]
)
)
Here’s context relevance metric:
context_relevance_metric = PointwiseMetric(
metric="context_relevance",
metric_prompt_template=PointwiseMetricPromptTemplate(
criteria={
"context_relevance": (
"Only check context and prompt. Ignore response. Is the context relevant to the prompt?"
),
},
metric_definition="Context relevance: Check to see if the context is relevant to the prompt",
rating_rubric={
"4": "The context is totally relevant to the prompt",
"3": "The context is somewhat relevant to the prompt",
"2": "The context is somewhat irrelevant to the prompt",
"1": "The context is totally irrelevant to the prompt",
},
input_variables=["prompt", "context"]
)
)
Here’s groundedness metric:
groundedness_metric = PointwiseMetric(
metric="groundedness",
metric_prompt_template=PointwiseMetricPromptTemplate(
criteria={
"groundedness": (
"Only check context and response. Ignore prompt. Is the response supported by the context?"
),
},
metric_definition="Groundedness: Check to see if the response is supported by the context",
rating_rubric={
"4": "The response is totally supported by the context",
"3": "The response is somewhat supported by the context",
"2": "The response is somewhat not supported by the context",
"1": "The response is totally not supported by the context",
},
input_variables=["prompt", "context"]
)
)
You combine them all into an evaluation:
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[answer_relevance_metric, context_relevance_metric, groundedness_metric],
experiment=get_experiment_name(__file__)
)
With that, you have the RAG triad implemented. See
pointwise_rag_triad.py
for details.
Run the evaluation for the RAG triad:
python pointwise_rag_triad.py all_metric
You should get detailed scores back for each metric:
==Metrics table==
prompt \
0 What is Cymbal Starlight?
1 Does Cymbal have an Anti-Lock braking system?
2 Where is the cargo area located?
3 What is the cargo capacity of Cymbal Starlight?
context \
0 Cymbal Starlight is a year 2024 car model
1 Maintain tire pressure at all times
2 The cargo area is located in the trunk of\nthe vehicle.
3 Cargo\nThe Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet.
response \
0 Sky is blue
1 The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet.
2 The cargo area located in the front of the vehicle
3 The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet.
answer_relevance/explanation \
0 The response is totally irrelevant to the prompt as it provides a statement about the sky's color instead of defining 'Cymbal Starlight'.
1 The response is completely irrelevant to the prompt, as the prompt asks about the presence of an Anti-Lock braking system while the response provi...
2 The response is totally relevant to the prompt as it answers the question of where the cargo area is located.
3 The response directly answers the question about the cargo capacity of the Cymbal Starlight.
answer_relevance/score \
0 1.0
1 1.0
2 4.0
3 4.0
context_relevance/explanation \
0 The context defines Cymbal Starlight as a 2024 car model, which is completely relevant to the prompt asking what Cymbal Starlight is.
1 The context provided is about tire pressure and the prompt asks about an anti-lock braking system which are both related to cars but are separate ...
2 The context is totally relevant to the prompt because it provides information about the location of the cargo area in a vehicle, which is exactly ...
3 The context provides information about the cargo capacity of the Cymbal Starlight, which is exactly what the prompt asks about, so it's totally re...
context_relevance/score \
0 4.0
1 1.0
2 4.0
3 4.0
groundedness/explanation \
0 The response is not supported by the context, as the context specifies Cymbal Starlight is a car model, while the response mentions 'Sky is blue'.
1 The response discusses the cargo capacity of a Cymbal Starlight 2024, which is not related to whether the Cymbal has an Anti-Lock braking system o...
2 The response states that the cargo area is in the front, but the context says that it is located in the trunk, so the response is not supported by...
3 The response is completely supported by the context provided, as it accurately states the cargo capacity of the Cymbal Starlight 2024.
groundedness/score
0 1.0
1 1.0
2 1.0
3 4.0
Conclusion
In this post, we covered model-based metrics, showed the built-in metrics, and showed how to define custom metrics, including the RAG triad. AI applications are becoming increasingly agentic, with tools and agents playing central roles. In the next post, we’ll explore how to evaluate tools and agents effectively.
References:
- Part 1: Gen AI Evaluation Service - An Overview
- Part 2: Gen AI Evaluation Service - Computation-Based Metrics
- Tutorial: Gen AI evaluation service - model-based metrics
- Documentation: Gen AI evaluation service overview
- Notebooks: GenAI evaluation service samples