In my previous Persisting LLM chat history to Firestore post, I showed how to persist chat messages in Firestore for more meaningful and context-aware conversations. Another common requirement in LLM applications is to ground responses in data for more relevant answers. For that, you need embeddings. In this post, I want to talk specifically about text embeddings and how Firestore and LangChain can help you to store text embeddings and do similarity searches against them.
Embeddings
Embeddings are numerical representations of text, images, or videos that capture relationships between them. Embeddings work by converting text, image, and video into arrays of floating point numbers called vectors. These vectors capture the meaning of the content. Later, you can calculate the numerical distance between the vectors and determine the similarity between content.
Embeddings are great but how do you generate, store, and search for them? To generate embeddings, you need to use an embedding model. Vertex AI supports two types of embedding models: text and multimodal.To store and search for embeddings, you need a vector database and Firestore can help!
FirestoreVectorStore
In Firestore, you can store embeddings in a special field and later perform a similarity search with find_nearest method of the collection. You can read more about it in Search with vector embeddings docs page. This is good but you have to generate embeddings yourself, set it to the right field, and later perform the similarity search against it. It’s a little tedious.
LangChain has a
VectorStore
abstraction that makes generating and storing embeddings easier. There’s also
Firestore for
LangChain
project and its FirestoreVectorStore implementation that simplifies embedding
storage and retrieval.
Here’s the basic usage of FirestoreVectorStore:
from langchain_google_firestore import FirestoreVectorStore
from langchain_google_vertexai import VertexAIEmbeddings
embedding = VertexAIEmbeddings(
model_name="textembedding-gecko@latest",
project=PROJECT_ID,
)
# Sample data
ids = ["apple", "banana", "orange"]
fruits_texts = ['{"name": "apple"}', '{"name": "banana"}', '{"name": "orange"}']
# Create a vector store
vector_store = FirestoreVectorStore(
collection=COLLECTION_NAME,
embedding_service=embedding,
)
# Add the fruits to the vector store
vector_store.add_texts(fruits_texts, ids=ids)
Afterwards, you can perform similarly search against the embeddings:
vector_store.similarity_search("I like fuji apples", k=3)
vector_store.max_marginal_relevance_search("fuji", 5)
You can see more examples in the FirestoreVectorStore notebook.
RAG with a PDF using LangChain and FirestoreVectorStore
Now that we understand the basics of embeddings and FirestoreVectorStore,
let’s put it together in a more complete example. Let’s image you want to use
PDFs as a Retrieval Augmented Generation (RAG) backend for your LLM application.
That way, you can get more relevant answers grounded in PDFs. In this case,
let’s use a single
cymbal-starlight-2024.pdf
file which is a user manual for a fictitious vehicle.
In a typical RAG pipeline, you first go through an ingestion phase where you split documents into smaller chunks, generate vector embeddings for each chunk and store in a vector database.
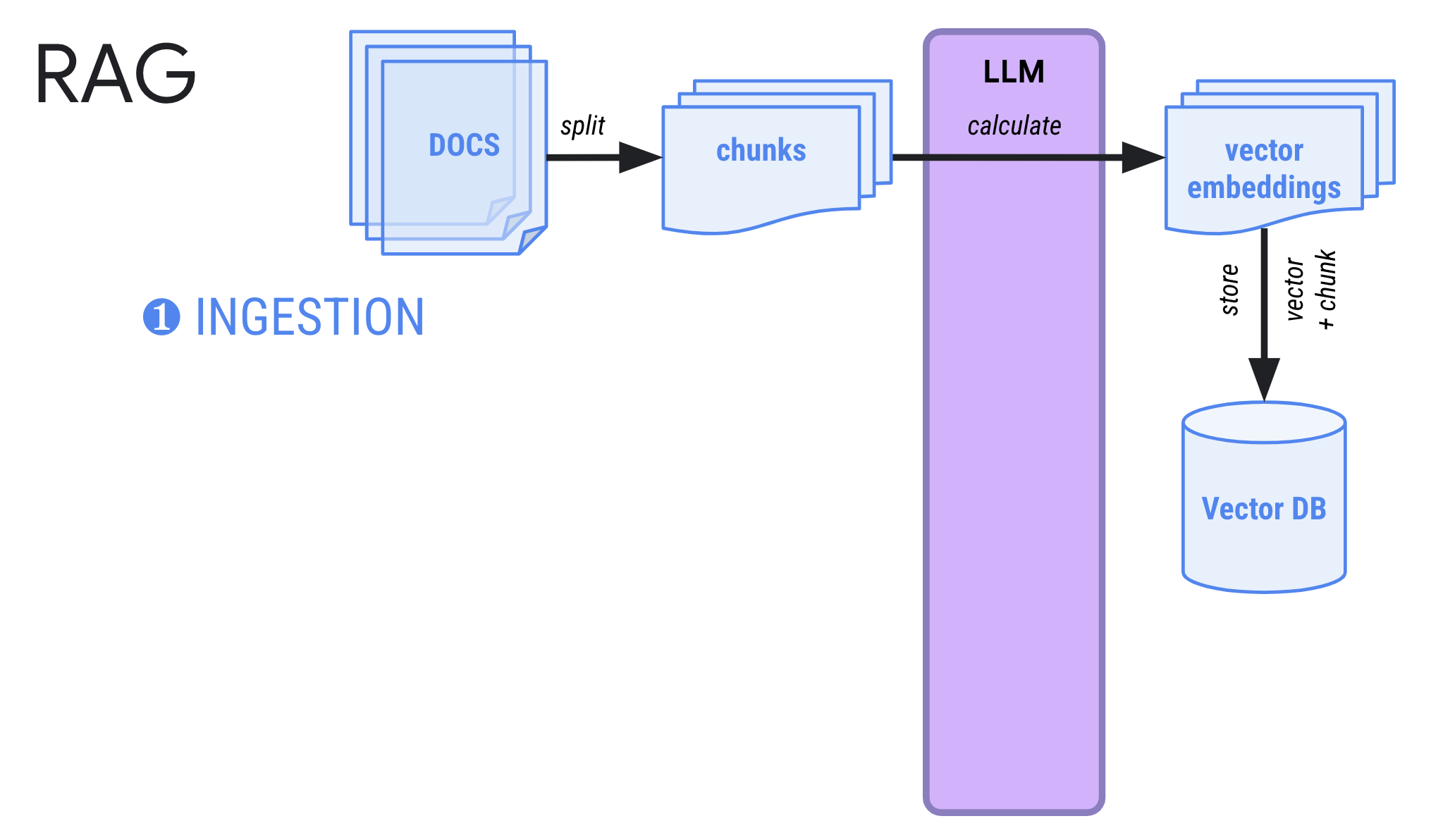
LangChain and Firestore makes the ingestion phase straightforward:
print(f"Load and parse the PDF: {args.pdf_path}")
loader = PyPDFLoader(args.pdf_path)
documents = loader.load()
print("Split the document into chunks")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
text_docs = text_splitter.split_documents(documents)
print("Initialize the embedding model")
embeddingsLlm = VertexAIEmbeddings(
project=args.project_id,
location="us-central1",
model_name="textembedding-gecko@003"
)
print("Create a vector store")
client = firestore.Client(
project=args.project_id,
database="pdf-database")
vector_store = FirestoreVectorStore.from_documents(
client=client,
collection="PdfCollection",
documents=text_docs,
embedding=embeddingsLlm)
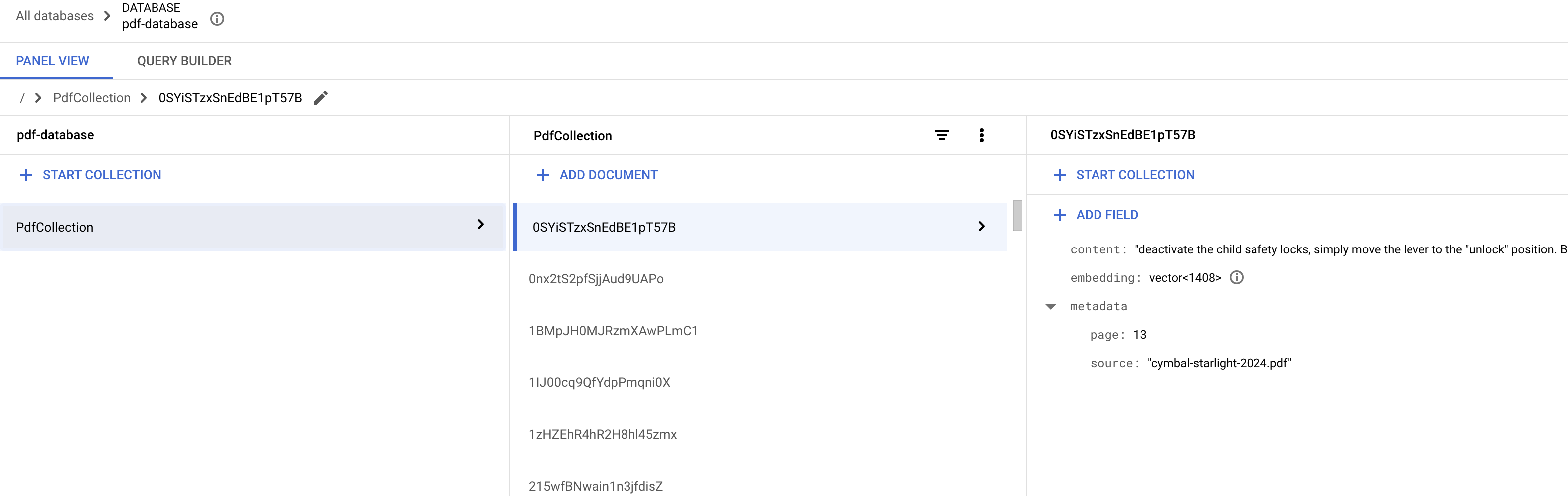
At the end of the ingestion phase, you will see the PDF chunks and embeddings stored in Firestore:
Later, in the querying phase, when a user asks a question in your LLM app, you can use the stored embeddings to find similar document chunks. Then, you can feed those similar chunks as additional context along with the prompt and that helps the LLM to give more relevant and grounded answers.
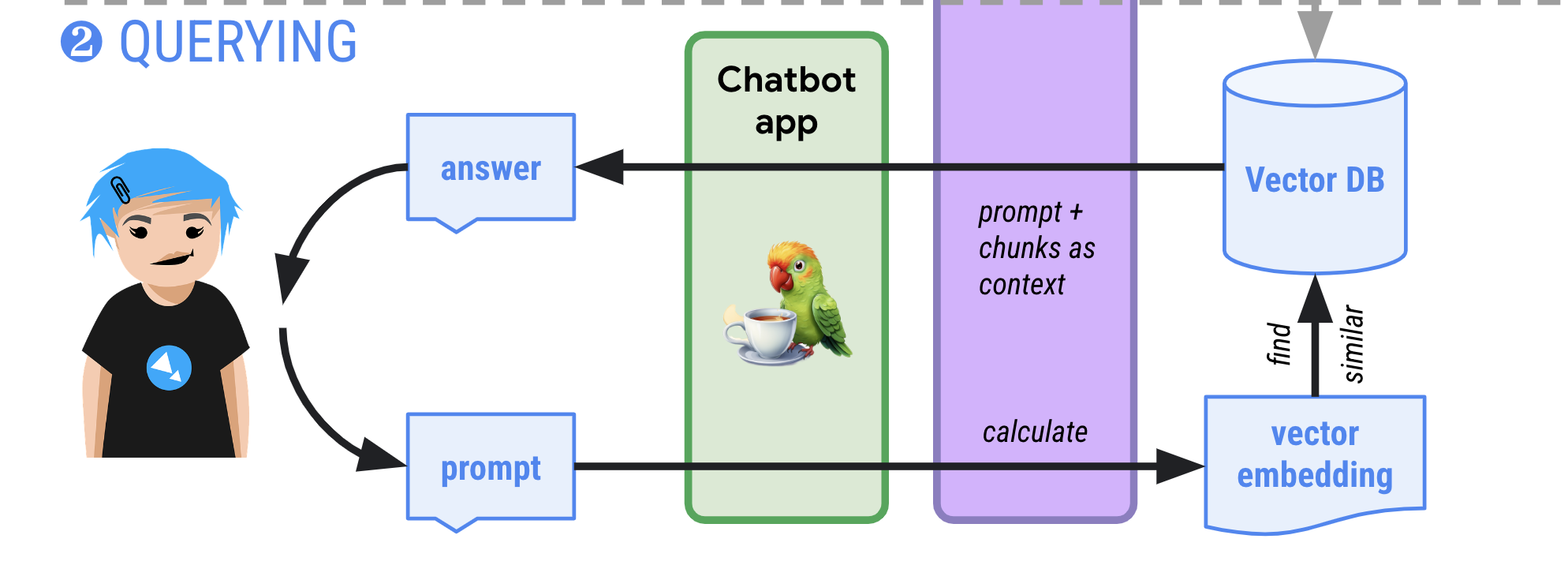
You set this up by accessing FirestoreVectorStore as a retriever and setting up
a RAG chain in LangChain:
retriever = vector_store.as_retriever()
print("Initialize the chat model")
llm = ChatVertexAI(
project=args.project_id,
location="us-central1",
model="gemini-1.5-flash-001"
)
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
"{context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
print("Create RAG chain")
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, question_answer_chain)
print("RAG is ready!")
return rag_chain
Once the RAG chain is ready, you simply invoke it with the prompt from the user:
response = rag_chain.invoke({"input": args.prompt})
print(f"Prompt: {args.prompt}")
print(f"Response: {response['answer']}")
LangChain takes care of retrieving similar documents from Firestore, adding them as context and giving you relevant answers grounded with the provided PDFs. Neat!
You can see the full source code in main.py.
Run the application with the RAG backend
To prove that our RAG pipeline actually works, let’s ask a question about the vehicle without RAG enabled:
python main.py --project_id your-project-id \
--prompt "What is the cargo capacity of Cymbal Starlight?"
You get a response where the LLM does not really know what Cymbal is:
Prompt: What is the cargo capacity of Cymbal Starlight?
Response: Please provide me with more context! "Cymbal Starlight" could refer to many things, such as:
* **A spaceship:** If it's a fictional spaceship, the cargo capacity would be determined by the story's creator.
* **A real-world ship:** If it's a real ship, you'd need to specify the type of ship and its name (e.g., "Cymbal Starlight" cargo ship, "Cymbal Starlight" yacht).
* **A vehicle:** It could also refer to a truck or other vehicle.
Now, let’s create a Firestore database and create an index on the collection that we’ll use to store PDF chunks:
gcloud firestore databases create --database pdf-database --location=europe-west1
gcloud firestore indexes composite create --project=your-project-id \
--database="pdf-database" --collection-group=PdfCollection --query-scope=COLLECTION \
--field-config=vector-config='{"dimension":"768","flat": "{}"}',field-path=embedding
Now, let’s run it with RAG enabled:
python main.py --project_id your-project-id \
--prompt "What is the cargo capacity of Cymbal Starlight?" \
--pdf_path="cymbal-starlight-2024.pdf"
First, you see RAG is setup:
Load and parse the PDF: cymbal-starlight-2024.pdf
Split the document into chunks
Initialize the embedding model
Create a vector store
Initialize the chat model
Create RAG chain
RAG is ready!
Then, you get a response back:
Prompt: What is the cargo capacity of Cymbal Starlight?
Response: The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. The cargo area is located in the trunk of
the vehicle. To access the cargo area, open the trunk lid using the trunk release lever located in the driver's footwell.
Yay, it works!
Conclusion
LLMs are trained on a vast amount of data, but they know little or nothing about data specific to your app or users. In this post, you learned how you can use LangChain and Firestore to implement a RAG chain based on PDF documents. This allows the LLM to answer questions grounded in PDFs and give more relevant answers. In the next post, we’ll explore how you can do the same for images!
Here are some links:
- RAG with a PDF using LangChain and Firestore Vector Store
- Build LLM-powered applications using LangChain
- Firestore for LangChain
- FirestoreVectorStore notebook