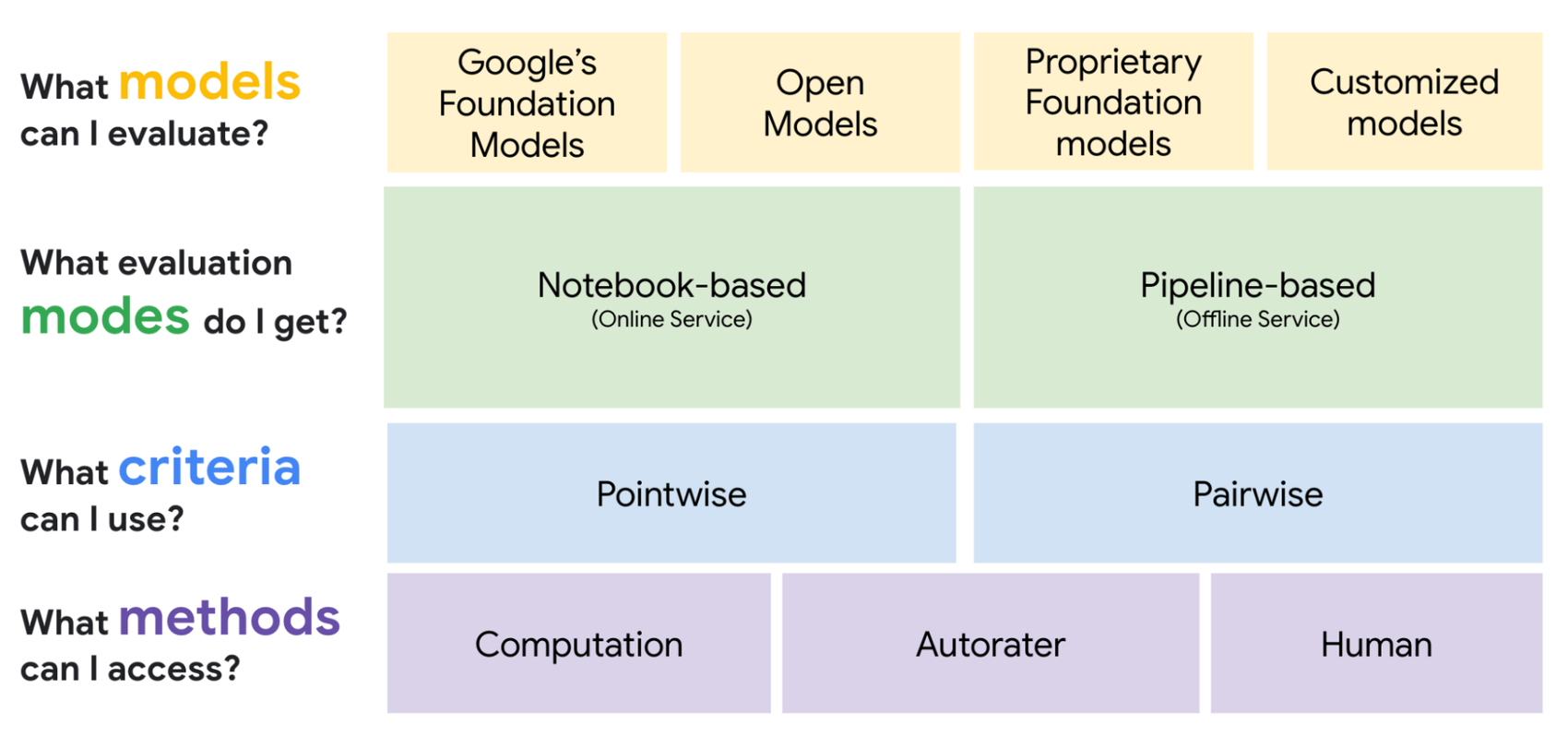
I’m continuing my Vertex AI Gen AI Evaluation Service blog post series. In today’s fourth post of the series, I will talk about tool-use metrics.
What is tool use?
Tool use, also known as function calling, provides the LLM with definitions of external tools (for example, a
get_current_weather function). When processing a prompt, the model determines if a tool is needed and, if so, outputs
structured data specifying the tool to call and its parameters (for example, get_current_weather(location='London')).