In my previous RAG Evaluation - A Step-by-Step Guide with DeepEval post, I showed how to evaluate a RAG pipeline with the RAG triad metrics using DeepEval and Vertex AI. As a recap, these were the results:
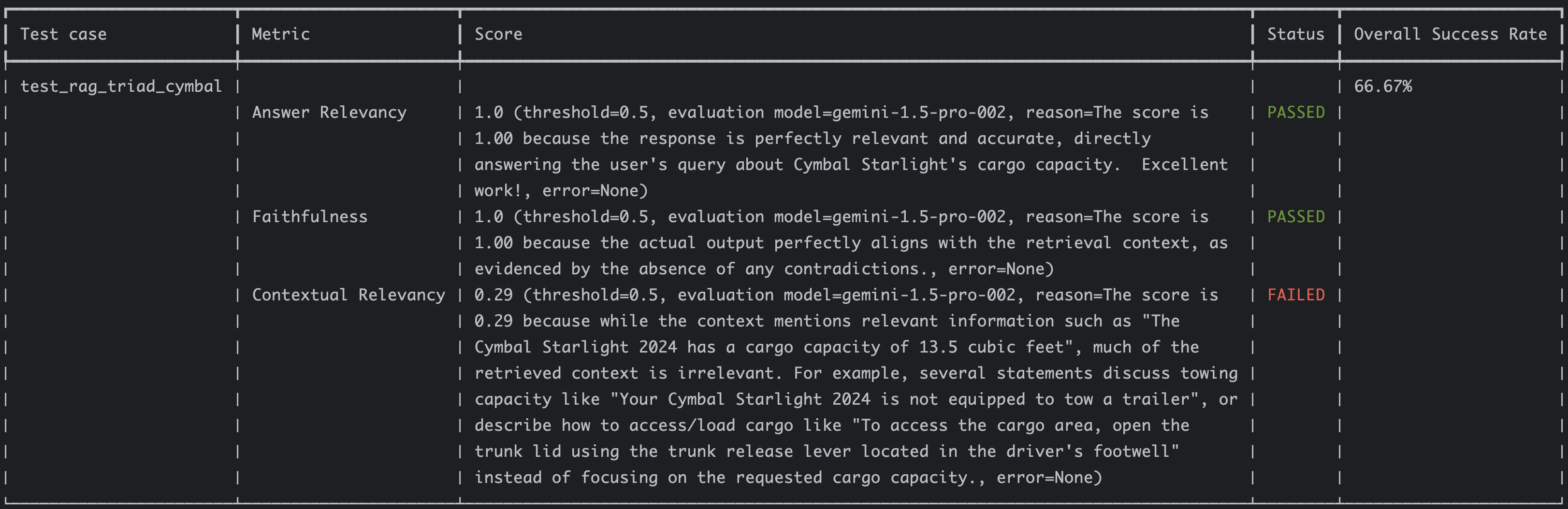
Answer relevancy and faithfulness metrics had perfect 1.0 scores whereas contextual relevancy was low at 0.29 because we retrieved a lot of irrelevant context:
The score is 0.29 because while the context mentions relevant information such as "The Cymbal Starlight 2024 has a cargo
capacity of 13.5 cubic feet", much of the retrieved context is irrelevant. For example, several statements discuss
towing capacity like "Your Cymbal Starlight 2024 is not equipped to tow a trailer", or describe how to access/load cargo
like "To access the cargo area, open the trunk lid using the trunk release lever located in the driver's footwell"
instead of focusing on the requested cargo capacity.
Can we improve this? Let’s take a look.
Read More →