In this post, I want to talk about an event-driven image processing pipeline that I built recently using Knative Eventing. Along the way, I’ll tell you about event sources, custom events and other components provided by Knative that simply development of event-driven architectures.
Requirements
Let’s first talk about the basic requirements I had for the image processing pipeline:
- Users upload files to an input bucket and get processed images in an output bucket.
- Uploaded images are filtered (eg. no adult or violent images) before sending through the pipeline.
- Pipeline can contain any number of processing services that can be added or removed as needed. For the initial pipeline, I decided to go with 3 services: resizer, watermarker, and labeler. The resizer will resize large images. The watermarker will add a watermark to resized images and the labeler will extract information about images (labels) and save it.
Requirement #3 is especially important. I wanted to be able to add services to the pipeline as I need them or create multiple pipelines with different services chained together.
Knative Eventing Goodness
Knative Eventing provides a number of components that help for building such as pipeline, namely:
- Eventing Sources allow you to read external events in your cluster and Knative-GCP Sources provide a number of eventing sources ready to read events from various Google Cloud sources.
- Broker and Trigger provide an eventing backbone where right events are delivered to right event consumers without producers or consumers having to know about how the events are routed.
- Custom Events and Event Replies: In Knative, all events are
CloudEvents. It’s useful to have a standard format
for events and various SDKs to read/write them. Moreover, Knative supports
custom events and event replies. Any service can receive an event, do some
processing, create a custom event with new data and reply back to
Brokerfor other services to read the custom event. This is very useful in pipelines where each service does a little bit of work and passes on the message forward.
Architecture
Here’s the architecture of the image processing pipeline. It’s deployed to Google Kubernetes Engine (GKE) on Google Cloud:
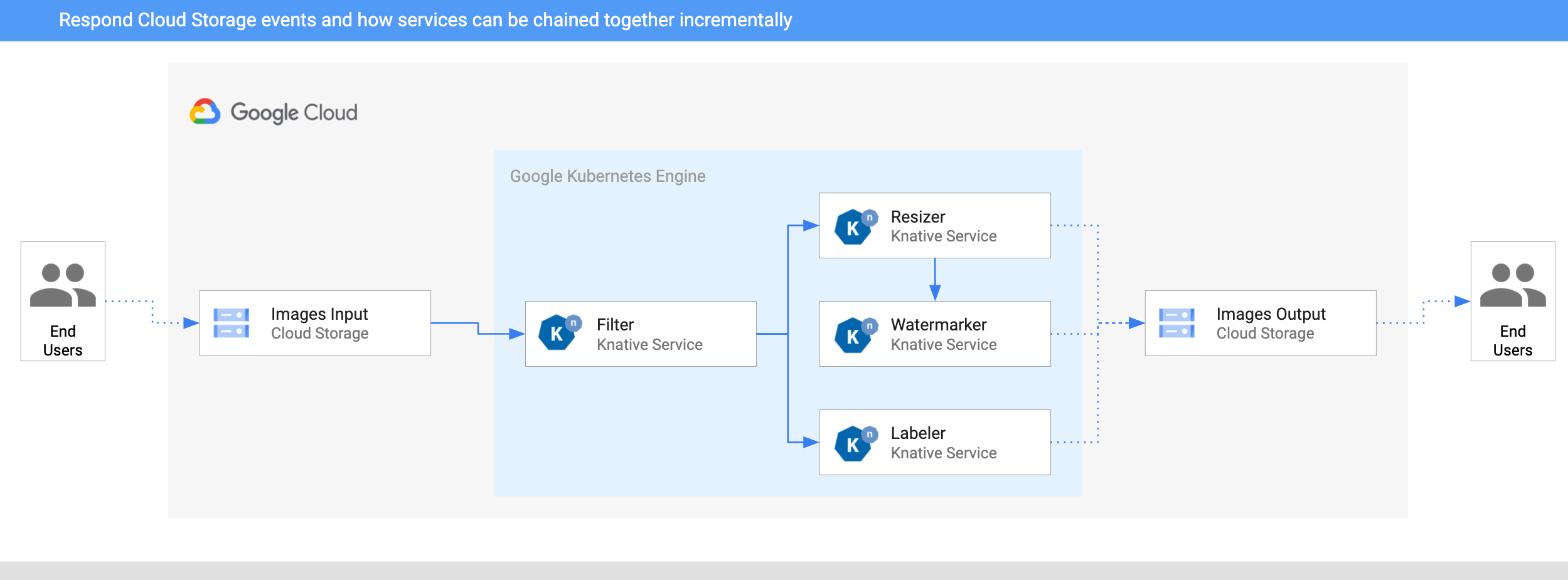
- An image is saved to an input Cloud Storage bucket.
- Cloud Storage update event is read into Knative by CloudStorageSource.
- Filter service receives the Cloud Storage event. It uses Vision API to
determine if the image is safe. If so, it creates a custom
CloudEventof typedev.knative.samples.fileuploadedand passes it onwards. - Resizer service receives the
fileuploadedevent, resizes the image using ImageSharp library, saves to the resized image to the output bucket, creates a customCloudEventof typedev.knative.samples.fileresizedand passes the event onwards. - Watermark service receives the
fileresizedevent, adds a watermark to the image using ImageSharp library and saves the image to the output bucket. - Labeler receives the
fileuploadedevent, extracts labels of the image with Vision API and saves the labels to the output bucket.
Build the pipeline
I have the instructions on how to build the pipeline and code and configuration in my Knative Tutorial. Let me highlight the main parts.
Read Cloud Storage events
To read Google Cloud storage events, you need to create a CloudStorageSource
and point to the bucket you want to listen events from:
apiVersion: events.cloud.google.com/v1alpha1
kind: CloudStorageSource
metadata:
name: storagesource-images-input
spec:
bucket: knative-atamel-images-input
sink:
ref:
apiVersion: eventing.knative.dev/v1beta1
kind: Broker
name: default
Once events are read in, they are fed into the Broker in default namespace.
Filter service
Filter service will get all the storage events and decide on which images are safe to pass on.
First, you need to create a Trigger to listen for
com.google.cloud.storage.object.finalize events:
apiVersion: eventing.knative.dev/v1beta1
kind: Trigger
metadata:
name: trigger-filter
spec:
filter:
attributes:
type: com.google.cloud.storage.object.finalize
subscriber:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: filter
Then, create the Knative Service to handle those events:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: filter
spec:
template:
spec:
containers:
- image: docker.io/meteatamel/filter:v1
env:
- name: BUCKET
value: "knative-atamel-images-input"
The code is in filter but the service basically uses Vision API to detect the safety of the image as follows:
private async Task<bool> IsPictureSafe(string storageUrl)
{
var visionClient = ImageAnnotatorClient.Create();
var response = await visionClient.DetectSafeSearchAsync(Image.FromUri(storageUrl));
return response.Adult < Likelihood.Possible
&& response.Medical < Likelihood.Possible
&& response.Racy < Likelihood.Possible
&& response.Spoof < Likelihood.Possible
&& response.Violence < Likelihood.Possible;
}
Once Filter service determines the picture is safe, it sends out a custom
CloudEvent of type dev.knative.samples.fileuploaded and the data field of the
CloudEvent is simply the bucket and file name:
var replyData = JsonConvert.SerializeObject(new {bucket = bucket, name = name});
await eventWriter.Write(replyData, context);
Resizer service
The code is here for resizer.
It only responds to dev.knative.samples.fileuploaded events as defined in its
trigger:
apiVersion: eventing.knative.dev/v1beta1
kind: Trigger
metadata:
name: trigger-resizer
spec:
filter:
attributes:
type: dev.knative.samples.fileuploaded
subscriber:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: resizer
It reads and resizes images using ImageSharp and emits another custom event
dev.knative.samples.fileresized for the next service watermarker to pick up.
Watermarker service
You can look at the details of Watermarker service in
watermarker
folder but in a nutshell, it receives events from resizer, reads resized image
and adds a Google Cloud Platform watermark to the image before saving it to
the bucket.
Labeler service
Labeler receives the same event that resizer receives. Instead, it uses Vision API to extract labels out of the image as follows:
private async Task<string> ExtractLabelsAsync(string storageUrl)
{
var visionClient = ImageAnnotatorClient.Create();
var labels = await visionClient.DetectLabelsAsync(Image.FromUri(storageUrl), maxResults: 10);
var orderedLabels = labels
.OrderByDescending(x => x.Score)
.TakeWhile((x, i) => i <= 2 || x.Score > 0.50)
.Select(x => x.Description)
.ToList();
return string.Join(",", orderedLabels.ToArray());
}
Then, it saves those labels to a text file in the output bucket.
Test the pipeline
If everything is setup correctly, you can see triggers in READY state:
kubectl get trigger
NAME READY REASON BROKER SUBSCRIBER_URI
trigger-filter True default http://filter.default.svc.cluster.local
trigger-labeler True default http://labeler.default.svc.cluster.local
trigger-resizer True default http://resizer.default.svc.cluster.local
trigger-watermarker True default http://watermarker.default.svc.cluster.local
I upload the folllowing picture from my favorite beach (Ipanema in Rio de Janeiro) to the bucket:

After a few seconds, I see 3 files in my output bucket:
gsutil ls gs://knative-atamel-images-output
gs://knative-atamel-images-output/beach-400x400-watermark.jpeg
gs://knative-atamel-images-output/beach-400x400.png
gs://knative-atamel-images-output/beach-labels.txt
We can see the labels Sky,Body of water,Sea,Nature,Coast,Water,Sunset,Horizon,Cloud,Shore in the text file and
the following resized and watermarked image:

Wrap up
As I mentioned, the complete
example
is on my Knative Tutorial repo. Our image pipeline is flexible, you can add and
remove services as you wish via triggers. This is the beauty of
event-driven architectures. Even though it’s a little more work to read and
write events (in this case CloudEvents), it allows a high degree of
flexibility.
If you have questions/comments, feel free to reach out to me on Twitter (@meteatamel).